Churn Rate Predict
Churn Rate
Se você oferece o mesmo serviço que seu concorrente, e ainda, por um preço melhor, por que o cliente não fica com o seu serviço?
Entender por que seus clientes abandonam o seu produto ou serviço é vital para conquistar um crescimento sustentável e lucrativo.
O Churn Rate pode lhe dar boas pistas sobre as escolhas dos clientes, mas afinal o que é isso???
Em uma tradução simples Churn Rate é a taxa de cancelamento, ou de abandono, registrada em sua base de clientes. por exemplo, para setores de serviço significa o cancelamento do serviço.

Embora tenha como principal função medir o percentual de clientes que abandonam um serviço, também serve para evidenciar o impacto negativo desses cancelamentos no caixa. Para alguns setores, esta é uma métrica básica para avaliar o sucesso do negócio, já que apresenta impacto direto no faturamento. Este é o caso dos serviços de assinatura.
É óbvio que a permanência ou não do cliente na empresa está relacionada a uma série de fatores. Mas a obrigação de todo gestor é partir do princípio de que o abandono foi causado por algum problema do seu lado do contrato.
Entender o Churn também pode auxiliar ao gestor identificar potenciais cancelamentos, com um tempo de antecedência, e promover ações direcionadas para tentar reter tais clientes. Ou seja, um alto valor para o churn rate é o que não desejamos.
Como o Churn tem um efeito negativo na receita de uma empresa, entender o que é esse indicador e como trabalhar para mitigar essa métrica é algo crítico para o sucesso de muitos negócios.
Esse estudo é uma provocação feita no curso Data Science na Prática onde fui desafiado a tentar explicar os passos e ferramentas aplicadas durante a evolução do material. Todo o material a ser desenvolvido no curso será centralizado no meu portfolio de projetos. Mais sobre o curso pode ser visto em: https://sigmoidal.ai.
1. O estudo
Nesse notebook elaborei um passo a passo detalhado para que seja possível replicar a análise dos dados disponível e recriar os modelos aqui demonstrados.
Foram utilizados diferentes modelos de Aprendizado de Máquinas. Primeiramente foi realizada verificação de equilíbrio e correções necessárias das variáveis e dados do dataset.
1.1 Suposições Inicias
Apesar de não haver informações explícitas disponíveis, os nomes das colunas nos permitem algumas suposições:
-
A variável alvo, que classifica se o cliente cancelou a assinatura é a
Churn; -
A coluna CustomerID representa o chave única do cliente na base de dados e pode ser excluída, pois não interfere nossa análise;
-
A variável
tenureestá relacionada ao tempo que um cliente permanece com a assinatura do serviço. Em outras palavras, pode-se dizer que é um indicativo de fidelidade; -
Apesar de não haver nenhuma documentação, assumo que a unidade de tempo utilizada é “mês”;
-
Podemos observar ainda outras informações do cadastro do cliente como outros serviços contratados, dados sobre a forma de pagamento, tipo de contrato, valores da última fatura e o total acumulado;
No notebook é possível se aprofundar nos estudos desses dados
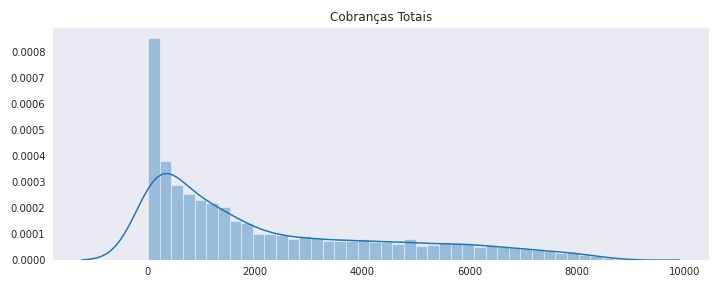
Por exemplo: Os passos para plotarmos o gráfico de distribuição das cobranças totais:
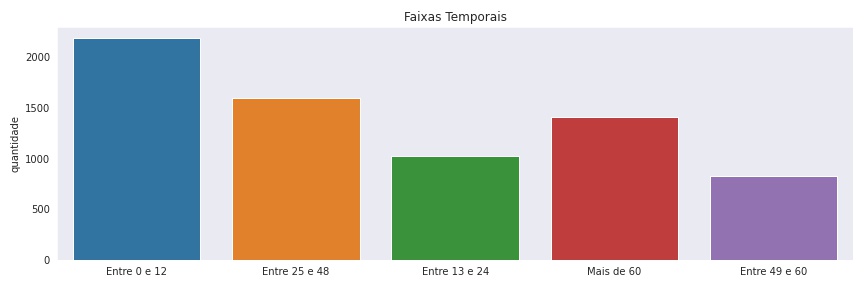
Ou como assumi algumas classificações para dividirmos a variável Ternure
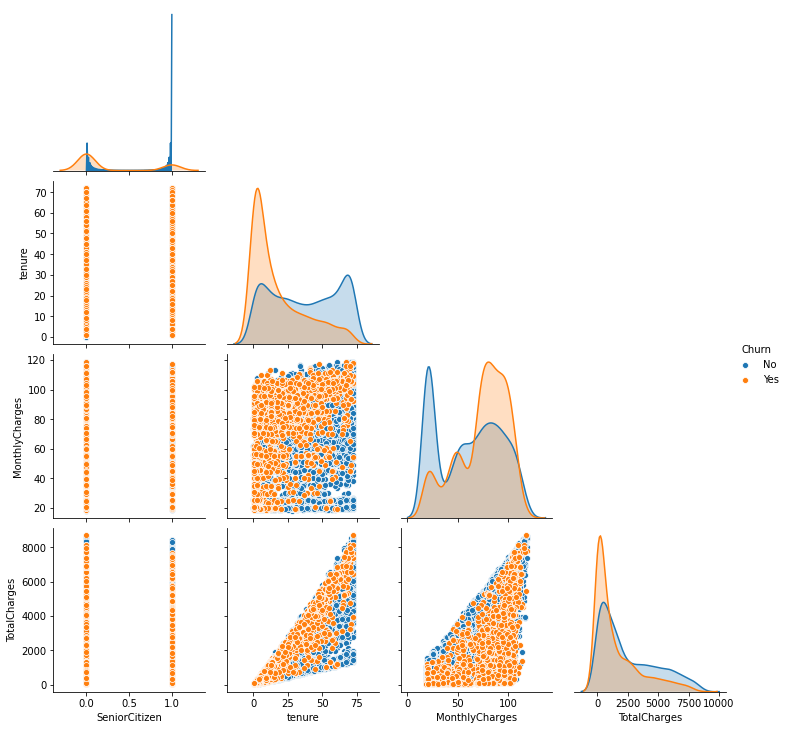
Então foi possível verificarmos a correlação entre as variáveis e a taxa de Churn :
2. Diferentes modelos de Machine Learning
2.1 Decision Tree
Primeiramente foi utilizado um modelo de Árvore de Decisões, pois não seria necessário realizar outras intervenções (padronizar e normalizar o dataset) e assim seria possível para obter um paramêtro para verificar em relação aos demais modelos.
#1. Escolha do modelo
from sklearn.ensemble import RandomForestClassifier
#2. Instanciar o modelo e optimizar hiper parâmetros
model_rf = RandomForestClassifier(max_depth=4, random_state=42)
#Separando os dados em features matrix e target vector
#3.1 Dividir o dataset entre treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
#4. Fit do modelo
model_rf.fit(X_train, y_train)
#5. Previsões
y_pred_rf = model_rf.predict(X_test)com esse modelo foi possível obter:

2.2 Demais modelos e o método Ensemble
Com os resultados obtidos no modelo inicial, os próximos passos seriam desenvolver novos modelos e compará-los com o modelo base a fim de comparar e verificar o desempenho.
Como explicado no post utilizei o método Ensemble para desenvolver paralelamente diversos modelos. A partir foi utilizado a métrica de votação hard para obtermos o resultado final desta etapa:
Deixarei no post o detalhamento utilizado da método:
# 1. importando bibliotecas necessárias
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.linear_model import SGDClassifier
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import VotingClassifier
# 2. Instanciar os modelos e definir hyperparametros
model_xgbc = XGBClassifier()
model_sgd = SGDClassifier()
model_svc = SVC()
model_lr = LogisticRegression()
model_dt = DecisionTreeClassifier()
voting_clf = VotingClassifier(estimators =[('xgbc', model_xgbc), ('sgd', model_sgd), ('svc', model_svc), ('dt', model_dt), ('lr', model_lr)], voting='hard')
# 3. Separar os dados
#os dados já foram separados anteiormente
# 3.1 Padronizar os dados
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.fit_transform(X_test)
# 4. Fit do modelo
for model in (model_xgbc, model_sgd, model_svc, model_dt, model_lr, voting_clf):
model.fit(X_train_scaled, y_train)
# 5. Fazer previsões em cima dos dados
model = []
accuracy = []
for clf in (model_xgbc, model_sgd, model_svc, model_dt, model_lr, voting_clf):
y_pred = clf.predict(X_test_scaled)
model.append(clf.__class__.__name__)
accuracy.append(accuracy_score(y_test, y_pred))
# 6. Verificando Acurácia dos modelos
col = ['Acuracia']
ac = pd. DataFrame(data=accuracy, index=model, columns=col)
acA partir do modelo acima os resultados de acurácia obtidos foram:
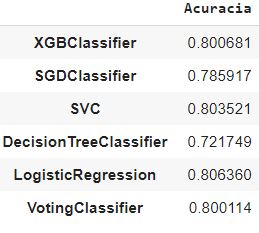
2.3 Validação Cruzada
Após a elaboração dos modelos paralelos foi utilizado o processo de Validação Cruzada para otimizar a amostra de dados e tentar obter uma melhora nos resultados
# Aplicando Validação Cruzada com K-Fold
from sklearn.model_selection import cross_val_score
accuracies = cross_val_score(estimator = voting_clf, X = X_train_scaled, y = y_train, cv = 10, verbose=3)
print("Acurácia: {:.2f} %".format(accuracies.mean()*100))Com a acurácia do modelo em torno de 80% os próximos passos foram otimizar os hiper parâmetros.
3. Otimização do Modelo
Nos próximos passos utilizei o modelo XGBoost Classifier e executei algumas rotinas de otimização dos hiper parâmetros.
3.1 Grid Search
O método Grid Search é uma abordagem de força bruta que testa todas as combinações de hiper parâmetros para encontrar o melhor modelo. Seu tempo de execução explode com o número de valores (e combinações dos mesmos) para testar.
Ao executar os testes durante a elaboração deste notebook exagerei nas combinações possíveis e levei quase 2 horas para que chegasse no valor final.
# 1. importar bibliotecas necessárias
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import GridSearchCV
# 2. Instanciar o modelo
xgb = XGBClassifier()
# 3. definir intervalos para otimização
# 3.1 Cross validation
kfold = StratifiedKFold(n_splits=5, shuffle=True)
#3.2 Intervalos para otimização
param_grid = {
'xgb__n_components': [0, 1, 5],
'xgb__n_estimators': range(0,200,50),
'xgb__learning_rate': [0.001, 0.01, 0.05],
'xgb__max_depth': [1, 2, 5],
'xgb__gamma': [0.01, 0.1, 1]
}
# 3.3 gerar o modelo
grid = GridSearchCV(xgb, param_grid, n_jobs=-1, scoring='recall', cv=kfold, verbose=3)
# 4. Fit do modelo
grid_result = grid.fit(X_train_scaled, y_train)
# 5. ver resultados
print("Melhor acurácia: {} para {}".format(grid_result.best_score_, grid_result.best_params_))3.2 Bayes Search
Além do método de Grid Search, podemos utilizar a biblioteca Scikit-Optimize é uma biblioteca Python de código aberto que fornece uma implementação de Otimização Bayesiana que pode ser usada para ajustar os hiperparâmetros de modelos de machine learning da biblioteca Python scikit-Learn.
Em contraste com GridSearchCV, nem todos os valores de parâmetro são testados, mas em vez disso, um número fixo de configurações de parâmetros é amostrado a partir do especificado distribuições.
O Bayes Search é a automação para tunning dos hiper parâmetros. É uma biblioteca relativamente nova que está em desenvolvimento e que facilita a nossa busca no refinamento dos hiper parâmetros.
# 1. importar as bibliotecas necessárias
import skopt
from skopt import BayesSearchCV
# 2. Definir intervalos de otimziação
bayes = BayesSearchCV(
estimator = XGBClassifier(
n_jobs = 1,
eval_metric = 'auc',
silent=1,
tree_method='auto'
),
# 2.1 Definindo intervalos de otimização
search_spaces = {
'learning_rate': (0.001, 1.0, 'log-uniform'),
'min_child_weight': (range(1,5,1)),
'max_depth': (0, 50),
'max_delta_step': (0, 20),
'subsample': (0.01, 1.0, 'uniform'),
'colsample_bytree': (0.01, 1.0, 'uniform'),
'colsample_bylevel': (0.01, 1.0, 'uniform'),
'reg_lambda': (1e-9, 1000, 'log-uniform'),
'reg_alpha': (1e-9, 1.0, 'log-uniform'),
'gamma': (1e-9, 0.5, 'log-uniform'),
'min_child_weight': (0, 5),
'n_estimators': (50, 100),
'scale_pos_weight': (1e-6, 500, 'log-uniform')
},
# 2. definindo método de avaliação
scoring = 'roc_auc',
cv = StratifiedKFold(
n_splits=3,
shuffle=True,
random_state=42
),
n_jobs = 3,
n_iter = 6,
verbose = 0,
refit = True,
random_state = 42
)
# callback handler
def status_print_bayes(optim_result):
bayes_resultado = bayes.best_score_
print("Melhor resultado: %s", np.round(bayes_resultado,4))
if bayes_resultado >= 0.98:
print('Suficiente!')
return True
# 4. Fit no modelo
otmizador = bayes.fit(X_train_scaled, y_train, callback=status_print_bayes)A partir da otimização Bayes os parâmetros que resultaram na melhor classificação foram: (‘colsample_bylevel’, 0.4160029192647807), (‘colsample_bytree’, 0.7304484857455519), (‘gamma’, 0.13031389926541354), (‘learning_rate’, 0.00885928719200224), (‘max_delta_step’, 13), (‘max_depth’, 21), (‘min_child_weight’, 2), (‘n_estimators’, 87), (‘reg_alpha’, 5.497557739289786e-07), (‘reg_lambda’, 648), (‘scale_pos_weight’, 275), (‘subsample’, 0.13556548021189216)
4. Modelo Final
Os resultados obtidos nos dois passos anteriores serviram para definir o modelo final
from scikitplot.metrics import plot_confusion_matrix, plot_roc
from sklearn.metrics import roc_auc_score, roc_curve
# modelo final
modelo_final = XGBClassifier(
learning_rate= 0.2700390206185342 ,
n_estimators= 83,
max_delta_step = 18,
max_depth= 36,
min_child_weight= 2,
gamma= 3.811128976537413e-05,
colsample_bylevel = 0.8015579071911014,
colsample_bytree = 0.44364889457651413,
reg_lambda= 659,
reg_alpha= 1.5057560255472018e-06,
)
modelo_final.fit(X_train_rus, y_train_rus)
# fazer a previsão
X_test = scaler.transform(X_test)
y_pred = modelo_final.predict(X_test)
# Classification Report
print(classification_report(y_test, y_pred))
# imprimir a área sob a curva
print("AUC: {:.4f}\n".format(roc_auc_score(y_test, y_pred)))
# plotar matriz de confusão
plot_confusion_matrix(y_test, y_pred, normalize=True)
plt.show()Com os dados desse modelo foi possível obter os seguintes resultados:
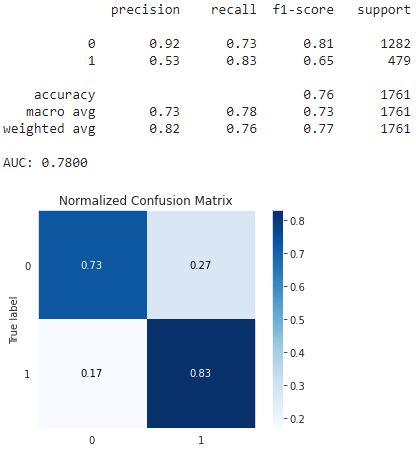
Optei por classificador ‘XGBClassifier’ devido as diversas possibilidades de refinamento.
Se fosse necessário o deploy desse classificador, bastaria utilizarmos o mesmo modelo com as otimizações que aqui criamos, validamos e testamos.
O classificador XGBoost otimizado obteve a performance com um Recall de 0.83%. No entanto, vale destacar que o Precision ficou baixo com um valor de 0.53. Isso significa que identificaríamos 83% dos clientes que realizariam churn, porém, também classificaríamos equivocadamente 36% dos clientes que não cancelariam os serviços. Ou seja, o trade-off entre Precision e Recall não ficou bom.
5. Verificando a Influência de cada Variável no modelo
SHAP (SHapley Additive exPlanations) é uma abordagem teórica de jogos para explicar a saída de qualquer modelo de Machine Learning.
Com o SHAP é possível verificar o peso que cada variável tem no classificador final. Com essa ferramenta é possível o gestor direcionar esforços nos itens que mais impactam o Churn Rate .
Na expliação oficial: essa abordagem conecta a alocação de peso ideal com explicações locais usando os valores clássicos de Shapley da teoria dos jogos e suas extensões relacionadas.
link para documentação oficial
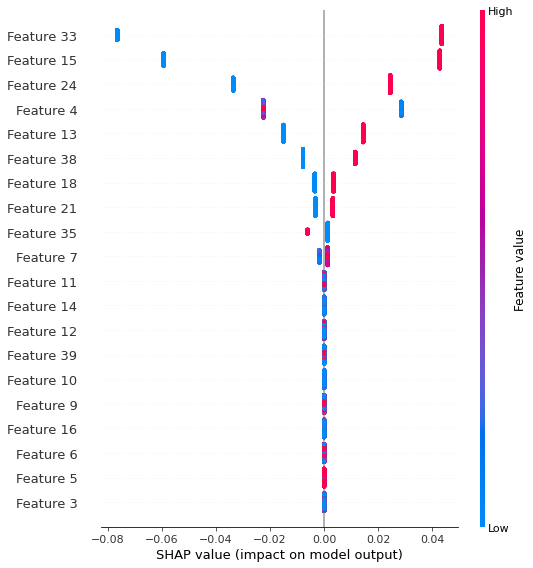
Utilizando a biblioteca SHAP podemos obsevar que as variáveis que mais influenciaram no nosso classificador são:
- Coluna33. Tipo de Contrato: Month to Month - contrato mensal
- Coluna15. Online Security: No - o cliente não possui serviço adicional de segurança online
- Coluna24. Tech Suport: No - o cliente não possui serviço adicional de suporte técnico
- Coluna4. Ternure: conforme já observado novos clientes estão mais propensos a cancelar o serviço
No notebook elaborado demonstro os passos de utilização dessa ferramenta incrível.
Conclusão
Compreender o Churn Rate , facilita que gestores e equipes atuem antecipadamente procurando reduzir os índices de cancelamentos e, assim, ampliar a sua base de clientes.
No modelo matemático criado a partir da base de dados fornecida foi possível observar que clientes com contratos mensais, sem serviços adicionais como segurança online e suporte técnico são mais suscetíveis ao cancelamento do serviço. Com os insights obtidos a empresa pode direcionar seus esforços e custos em pontos críticos e assim modificar o Churn Rate .