
Panorama COVID-19
A pandemia de Covid-19, causada pelo vírus SARS-CoV-2 ou Novo Coronavírus, vem produzindo repercussões em escala global, com impactos sociais, econômicos, políticos e culturais sem precedentes na história recente das epidemias.
Nesse notebook criei um passo a passo de como utilizar um dataset com os dados de acompanhamento do site World in Data para explorar a evolução da pandemia pelo mundo.
Análise Exploratória dos Dados
Câmeras com inteligência artificial são capazes de identificar doenças de pele, programas estão sendo usados para análises laboratóriais auxiliando médicos e pacientes no tratamento das mais diversas doenças. Esses novos recursos permitem intervenções eficientes e eficazes.
Essas novas ferramentas têm um ponto em comum a ciência de dados.
Cada vez mais dados das vitais, consultas médicas, exames laboratóriais são utilizados de forma sistemática. A partir da utilização desses dados a medicina vem ganhando novos capítulos, a ciência de dados está auxilando em tratamentos e diagnósticos.
Através da analise exploratória de dados pretendo demonstrar como a pandemia está evoluindo no mundo.
No notebook demonstrei como obter dados para a análise inicial, exemplo: identificação do dataset utilizado; consultar as dimensões do dataset número de variáveis e entradas totais; como imprimir a lista de headers (colunas);
Após esses passos foi demonstrado como corrigir as informações das viáveis e uma abordagem inicial para tratamento dos dados ausentes.
Comparando os dados
Após a análise inicial mostro como comparar os dados obtidos.
Verificando os casos reportados:
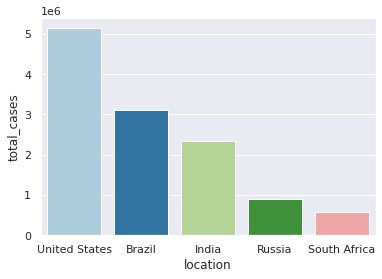
Utilizando a sintaxe podemos consultar no dataframe os países com mais casos reportados:
print("A classificação dos países com mais casos de Covid-19 em {} é:".format(print_recente))
#usando a função .loc para restringir a pesquisa na data mais recente ordernar os valores por total de casos
df_total_cases = df.loc[df.date == data_recente].sort_values(by="total_cases", ascending=False)
df_total_cases.iloc[1:6,]
Normalizando as populações e quantidade de casos
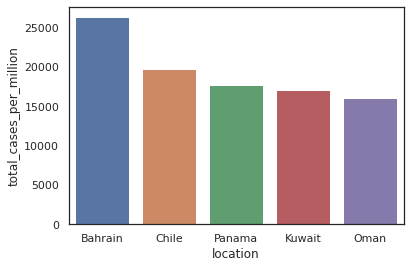
A fim de permitir uma melhor análise comparativa é preciso normalizar a população dos países, pois permitirá uma análise de casos pela proporção de habitantes.
print("Os países que apresentaram mais de 1.000 casos confirmados, normalizando a contagem de casos por milhão de habitantes em {} é:".format(print_recente))
df_total_cases_per_million = df.loc[df.date == data_recente].sort_values(by="total_cases_per_million", ascending=False)
df_total_cases_per_million = df_total_cases_per_million.loc[df_total_cases_per_million.total_cases >= 1000].sort_values(by="total_cases_per_million", ascending=False)
df_total_cases_per_million.iloc[1:6,]
Visualização dos dados
Para facilitar a análise comparativa plotei os dados das análises anteriores.
Casos totais reportados
Casos totais para população normalizada
Escolhendo os países para análise
Ao fim do notebook através de um formulário no Colab podemos selecionar o país desejado e verificar os dados analisados. Deixo aqui um exemplo de sintaxe para elaboramos um gráfico em Seaborn com um eixo secundário onde podemos observar os novos casos em relação ao número de casos acumulados:
plt.close()
#criar o objeto gráfico
f, ax8 = plt.subplots(figsize=(10, 5))
#dados para o gráfico de barra barplot
ax8 = sns.barplot(x='week_number', y='new_cases', data=df_search, palette='summer') #define os dados para o gráfico de barra
ax8.set_xlim(0,)
#adicionar anotação da primeira morte registrada
#no campo xy=(,) indica as coordenadas onde a seta começa, no campo xytext=(,) indica as coordenadas onde o texto começa e termina a seta
ax8.annotate('primeira morte registrada', xy=(first_week, 2), xytext=(1, first_week+(max_casos/4)),
arrowprops=dict(facecolor='red', shrink=0.05))
ax9 = ax8.twinx() #passamos a informação que o eixo x é o mesmo e utilizaremos um eixo y secundário
# dados para o gráfico de linha
sns.lineplot(x='week_number', y='total_cases', data = df_search, ax=ax9, color="red")
#define os valores iniciais e finais dos eixos
ax9.set_xlim(0, max_week)
ax9.set_ylim(0,)
#definir título e nome dos eixos
ax8.set_title("Acompanhamento de Casos para {}." .format(escolha_o_pais), fontsize=16)#define os dados para o gráfico de linha
ax8.set_ylabel("Novos Casos")
ax8.set_xlabel("Semana")
#apagar o número da semana do eixo x
ax8.xaxis.set_major_formatter(plt.NullFormatter())
plt.show()e obtemos a seguinte imagem:
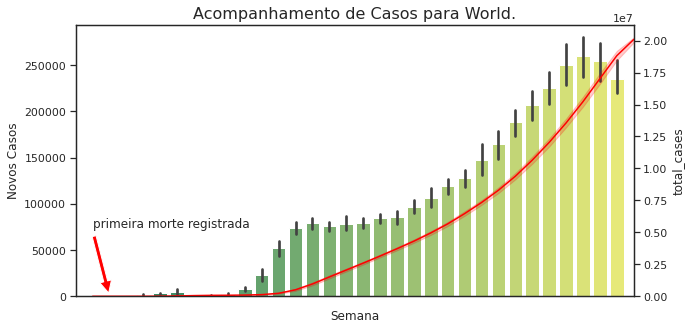
Conclusão
Um detalhe extremamente importante a ser destacado é que esses dados são medidos diariamente, e esse conjunto de dados ficará desatualizado “rapidamente”.
Entretanto, levando em consideração o contexto dos dados analisados na primeira parte desse notebook, vale a pena destacar que:
- Os Estados Unidos estão disparados em relação aos casos e mortes.
- A evolução dos casos no Brasil está em crescimento.
- No geral, casos e mortes ainda estão crescendo.
- A letalidade da pandemia foi maior nas primeiras semanas e hoje encontra-se em uma curva decrescente. Muitas outras análises podem ser retiradas desse conjunto de dados, mas com essa análise inicial já conseguimos obter algumas hipóteses.
Data Science na Prática
O material aqui desenvolvido é parte da provocação feita no curso de Data Science na Prática onde fui desafiado a tentar explicar os passos e ferramentas aplicadas durante a evolução do material. Todo o material a ser desenvolvido no curso será centralizado no meu portfolio de projetos.