
Análise de Risco de Default
Avaliação de Risco de Crédito
Como um modelo de machine learning pode influenciar na taxa de juros que você paga no cartão de crédito???
Com a crise econômica gerada pela pandemia de Covid-19, até os grandes bancos brasileiros reforçaram provisões para o caso de clientes que não cumpram com suas obrigações financeiros, ou seja, o não pagamento de suas dívidas, o que afetou diretamente o resultado destas instituições.
Com o rápido aumento na disponibilidade de dados e na capacidade de computação, a área de Machine Learning agora desempenha um papel vital no setor financeiro. Modelos de Machine Learning estão contribuindo significativamente para modelagem de risco de crédito. Grandes bancos e Fintechs têm apostado cada vez mais em modelos de Machine Learning para prevenir a inadimplência de alguns clientes e assim ajustar suas taxas de juros aos clientes finais.

Neste notebook você pode encontrar todos os passos para recriar o modelo que será demonstrado aqui nesse post e observar as etapas que aqui serão comentadas.
Dentre as principais instituições financeira, o Nubank é uma das que mais tem se destacado no uso de Inteligência Artificial e times de Data Science.
O conjunto de dados a ser utilizado neste Projeto de Data Science parte de uma competição realizada pela fintech Nubank a fim de revelar talentos e potenciais contratações pela Fintech.
Esse estudo é uma provocação feita no curso Data Science na Prática onde fui desafiado a tentar explicar os passos e ferramentas aplicadas durante o desemvolvimento desse projeto. Todo o material a ser desenvolvido durante o curso e nos demais proejtos poderão ser vistos também no meu portfolio de projetos. Mais sobre o curso pode ser visto em: https://sigmoidal.ai.
1. Contextualização do Problema
Neste problema, o objetivo é identificar um cliente da Startup Nubank que não cumprirá com suas obrigações financeiras e deixará de pagar a sua fatura do Cartão de Crédito default.
Vale ressaltar que essa avaliação deve ser realizada quando o cliente solicita o cartão (normalmente no primeiro contato com a instituição).
OBJETIVO : Criar um modelo que avalie se um cliente ficará inadimplente.
Espera-se que um modelo seja capaz de minimizar as perdas financeiras do Nubank, porém minimizando também os falsos positivos.
1.1 Primeira etapa
Os dados utilizados nesta análise estão disponíveis para download por meio deste link. Consiste basicamente em um arquivo csv contendo 45.000 entradas e 43 colunas.
Após importarmos os dados iremos fazer uma análise exploratória dos dados:
1.1.1 Preposições iniciais
-
A coluna
idsé anônima e representa o identificador único do cliente. Normalmente essa coluna não influência no modelo de machine learning. -
A coluna
target_defaulté o nosso alvo. Essa coluna representa no dataset se o cliente cumpriu ou não com as obrigações junto a instituição financeira. -
As colunas
score_1escore_2estão codificadas de alguma forma. As colunasscore_3,score_4,score_5escore_6são numéricas. Essas variáveis classificam o cliente quanto a pontuação de crédito e iremos verificar a quantidade de códigos para analisar a sua transformação para categorias. -
existem outras variáveis que apresentam algum tipo de codificação, como [‘reason’, ‘state’, ‘zip’, ‘channel’, ‘job_name’, ‘real_state’] que estão codificadas e também precisarão de alguma análise mais aprofundada para saber se é possível extrair alguma informação das mesmas.
-
A coluna
lat_lonestá em formato string contendo uma tupla com as coordenadas. A colunashipping_zip_codeé referente ao CEP do canal de comunicação indicado pelo cliente, assim como a colunazipprovavelmente representa o CEP do imóvel onde o empréstimo foi realizado. -
As colunas
last_amount_borrowed,last_borrowed_in_months,credit_limitindicam a existência de empréstimos, quando o último empréstimo foi realizado e o limite de crédito para o cliente.
Do resumo estatístico podemos ainda observar:
df.describe()-
A coluna
external_data_provider_credit_checks_last_2_yearpossui praticamente metade dos valores ausentes e valores máximo, mínimos e desvio padrão igual a 0 (zero), portanto não será útil nas avaliações. -
A coluna
external_data_provider_email_seen_beforepossui um valor -999 e irá distorcer as análises futuras. -
A coluna
reported_incomepossui valores infinitos, pelo rótulo da coluna podemos inferir que representa os valores informados de recebíveis do cliente. Podemos substituir esse outlier pela mediana dos valores.
No próximo passo iremos verificar o tipo das variáveis que compõe o Dataset para separarmos as variáveis categóricas:
1.1.2 Análise dos dados ausentes
Da análise dos dados ausentes identificamos:
print((df.isnull().sum() / df.shape[0]).sort_values(ascending=False))-
Diversas variáveis como
['target_fraud', 'last_amount_borrowed', 'last_borrowed_in_months', 'ok_since', 'external_data_provider_credit_checks_last_2_year']possuem mais da metade dos valores ausentes. -
As variáves [‘external_data_provider_credit_checks_last_year’, ‘credit_limit’, ‘n_issues’] possuem entre 25-34% do seus valores ausentes.
-
A variável alvo
target_defaultcontém valores nulos que serão eliminados do dataset.
Neste projeto, o caso mais extremo target_fraud não representa um problema, pois é uma variável alvo que não interessa para a análise de risco de inadimplência. A mesma possui praticamente 97% dos dados ausentes. Já as demais features deverão ser usadas com o devido cuidado.
Uma outra análise interessante foi feita diz respeito à contagem de valore únicos por features. Muitas vezes, variáveis numéricas podem esconder classes/categorias que melhor representariam uma feature, ou revelar uma quantidade elevada de classes para “variáveis categóricas”.
print(df.nunique().sort_values())Novamente em relação a variável external_data_provider_credit_checks_last_2_year foi possivél observar que há algum distorção em relação aos dados fornecidos. Nessa etapa observamos também que a coluna channel possui apenas um valor. Como não há maiores informações sobre estes dados eles foram excluidos para que não interfiram nas próximas etapas.
Também é possível observar que a coluna profile_phone_number possui 45.000 entradas únicas e provavelmente não traria nenhuma contribuição relevante ao modelo.
Na sequência as linhas que não estavam preenchidas na variável alvo foram excluídas. Ainda foi gerado um gráfico para compararmos nossa variável alvo para verificar o balanceamento das categorias
1.1.3 Balanceamento dos Dados
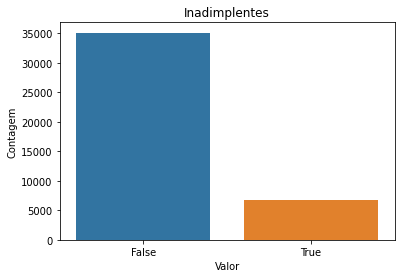
Pelo gráfico anterior foi possível obserar, como já esperado, que estamos lidando com um dataset desbalanceado (imbalanced dataset): Amostas: Total: 41741 Positivos: 6661 (15.96% of total)
Adiante foi necessário tratarmos esse ponto, para não prejudicarmos os modelos de machine learning.
Continuando a exploração de dados, ainda gerei um gráfico de dispersão (scatter plot) comparando as variáveis income e credit_limit.
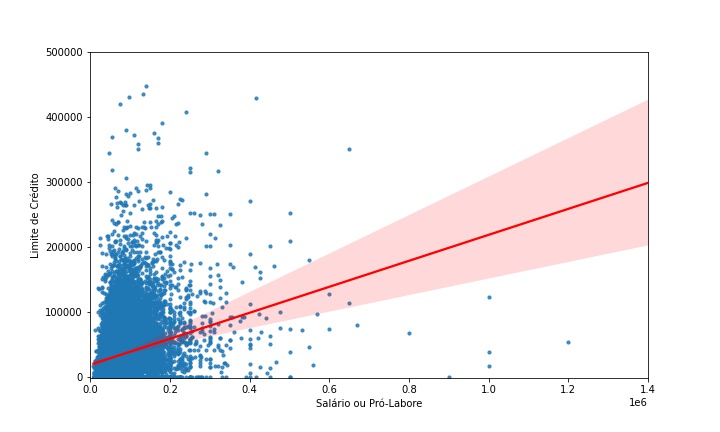
Do gráfico anterior é possível observar pela linha vermelha que conforme o income (ou salário / pró-labore) aumenta, o limite de crédito também se eleva (indica uma correlação positiva), porém existem algumas distorções na base de dados, pois alguns limites de crédito são bem elevados em relação ao outro parâmetro.
2. Divisão de Dados entre treino e teste
Como a divisão do conjunto de dados em conjuntos de treinamento e teste é feita de forma aleatória, deve ocorrer antes da normalização / padronização dos dados.
Isso é especialmente importante com conjuntos de dados desbalanceados, onde o overfitting é um problema significativo devido à falta de dados de treinamento.
Por que isso seria problema?
Com tão poucas observações verdadeiras em relação as falsas, o modelo de treinamento passará a maior parte do tempo em exemplos falsos e não aprenderá o suficiente com os verdadeiros. Por exemplo, se o tamanho da sua subdivisão de dados (ou lote) for 128, muitas amostras não terão exemplos verdadeiros, então os gradientes serão menos precisos.
A divisão dos dados foi feita utilizando a API do Scikit Learning train_test_split, separando um amostra de 20% para os futuros testes.
Neste post não vou entrar em detalhes, mas caso fique alguma dúvida por favor deixe nos comentários.
Dataset original Amostas: Total: 41741 Positivos: 6661 (15.96% of total)
Dataset de treino Amostas: Total: 33392 Positivos: 5397 (16.16% of total)
3. Normalização e Categorização dos dados
Após a separação dos dados entre treino e teste, foi feita o scaling dos dados, ou seja normalização. Tão pouco entrerei em detalhes nesse posto, mas confira no notebook os passos desta etapa.
No processo de categorização dos dados, onde as variáveis categóricas foram transformadas para números o processo adotado foi o LabelEncoder.
#1. importando as bibliotecas necessárias
from sklearning.preprocessing import LabelEncoder
from collections import defaultdict
#2. obter apenas as variáveis categóricas
cat_X = X_train.select_dtypes(include='object').column
#3. criando um dicionário de dados
label_dict = defaultdict(LabelEncoder)
#4. instanciando o encoder
label = LabelEncoder()
#5. fit do encoder
df_clean.aplly(lambda i: label_dict[i.name].fit(i))
#aplicando o encoder para os dados de treino e teste
X_train.loc[:,cat_X] = X_train.loc[:,cat_X].aplly(lambda i:label_dict[i.name].transform[i])
X_test.loc[:,cat_X] = X_test.loc[:,cat_X].aplly(lambda i:label_dict[i.name].transform[i])No passo anteior transformamos as variáveis categóricas em números e aplicamos ao dataset de treino e testes.
Não se esqueça de acompanhar no notebook como a variável alvo foi transformada em 1 e 0.
Agora com as variáveis categóricas tansformadas em variáveis numéricas, podemos continuar nossa analise de dados e verificar qual a correlação entre os dados:
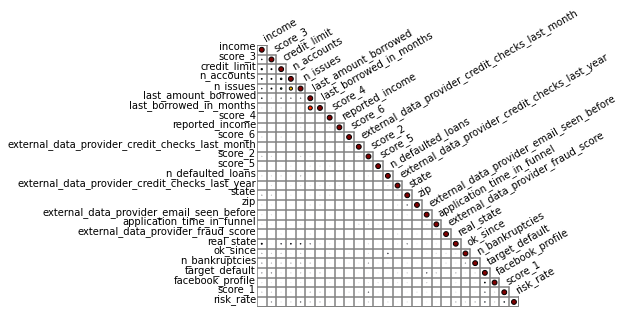
Do gráfico anterior é possível observar que a correlação entre as variáveis do dataset e a variável alvo são muito fracas.
Uma obsevação: para elaborar esse gráfico utilizei a biblioteca biokit, pois na minha opnião apresenta uma visualização mais limpa dos dados.
Uma outra forma de verificar a correlação entre as variáveis é fazendo um gráfico de pares:
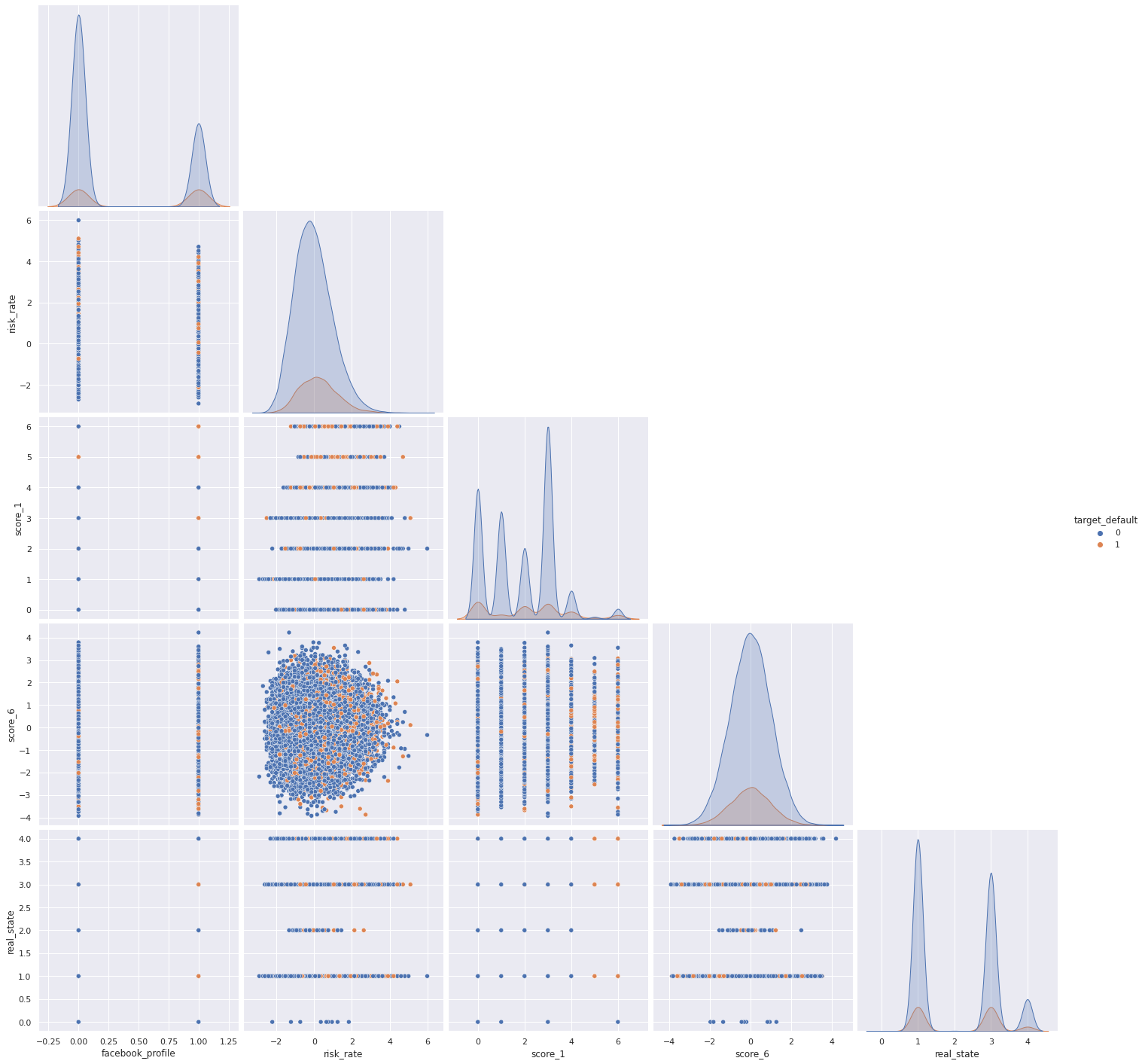
Depois de rever nossas distribuições, correlações e visualizá-las agrupadas, vamos rever alguns insights:
Correlações fracas entre as variável alvo e outras variáveis disponível.
Variáveis inesperadas como as mais correlacionadas.
O número de empréstimos anteriores inadimplentes influencia fortemente o limite de crédito.
Renda mais alta não significa necessariamente limite de crédito mais alto.
2. Diferentes modelos de Machine Learning
Para este desafio utilizei método Ensemble com os hyper parâmetros no modo padrão e depois comparmos os resultados obtidos com um modelo refinado, vamos ver os passos. Lembre-se que você pode checar todos os detalhes diretamente no notebook
2.1 O método Ensemble
Como explicado no post utilizei o método Ensemble para desenvolver paralelamente diversos modelos. A partir foi utilizado a métrica de votação hard para obtermos o resultado final desta etapa:
Deixarei no post o detalhamento utilizado da método:
#importando bibliotecas necessárias
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import SGDClassifier
from xgboost import XGBClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.metrics import roc_auc_score, roc_curve, accuracy_score, confusion_matrix, classification_report
#2. Instanciando os modelos
model_xgbc = XGBClassifier()
model_sgd = SGDClassifier()
model_svc = SVC()
model_dt = DecisionTreeClassifier()
model_rf = RandomForestClassifier()
voting_clf = VotingClassifier(estimators=[('xgbc', model_xgbc), ('sgd', model_sgd),
('svc', model_svc),
('dt', model_dt), ('rf', model_rf)],
n_jobs=-1 , voting='hard')
#3. os dados já foram separados anteriormente
#4. Fit do modelo
for model in (model_xgbc, model_sgd, model_svc, model_dt, model_rf, voting_clf):
model.fit(X_train, y_train)
#5. Fazendo previsões em cima do modelo treinado
model = []
accuracy = []
roc_score = []
for clf in (model_xgbc, model_sgd, model_svc,
model_dt, model_rf, voting_clf):
y_pred = clf.predict(X_test)
model.append(clf.__class__.__name__)
accuracy.append(accuracy_score(y_test,y_pred))
#6. Verificando resultados
col = ['Acurácia']
resultado = pd.DataFrame(data=accuracy, index=model, columns=col)
resultadoA partir do modelo acima a acurácia obtida foi:

Podemos verificar ainda qual a importância de cada variável nos modelos desenvolvidos, utilizei como exemplo modelo Random Forest:
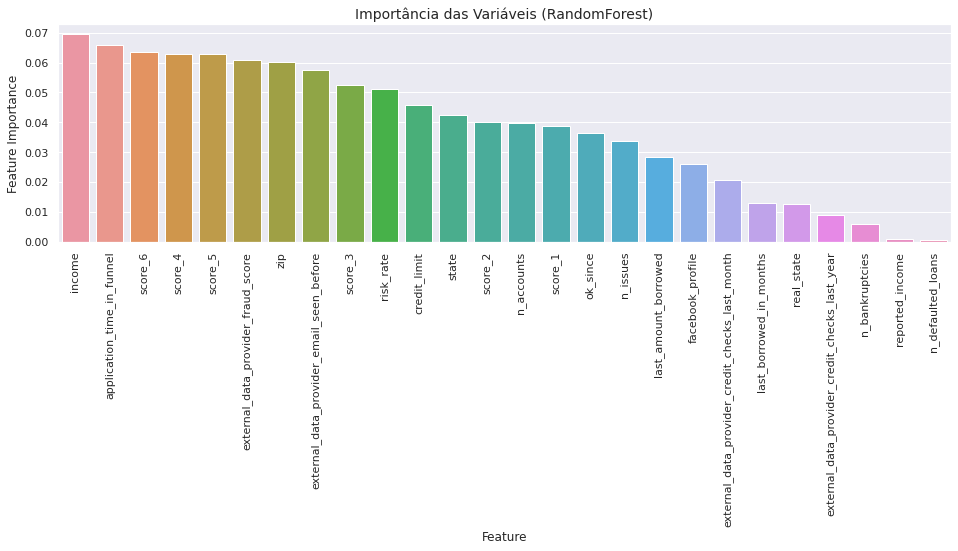
Os passos para gerar o gráfico são:
#RandomForest Feature Importance
tmp = pd.DataFrame({'Feature': predictors, 'Feature Importance': model_rf.feature_importances_})
tmp = tmp.sort_values(by='Feature Importance', ascending=False)
plt.figure(figsize=(16,4))
plt.title('Importância das Variáveis (RandomForest)', fontsize=14)
s = sns.barplot(x='Feature', y='Feature Importance', data=tmp)
s.set_xticklabels(s.get_xticklabels(),rotation=90)
plt.show();
plt.savefig("Default-feature_importance.jpg")
plt.close()2.2 eXtreme Gradient Boosting ou XGBoost
Do método Ensemble podemos observar que o XGBoost apresentou boa acurácia, portanto iremos utilizá-los nos próximos passos para ajustes e refinamentos dos hiper parâmetros.
Como visto anteriormente estamos desenvolvendo modelos a partir de um dataset desbalanceado, o XGBoost permite ajustar um dos hyper parâmetros para refletir o peso de cada amostra, uma das técnicas é utilizar o scale_pos_weight, mais sobre o assunto pode ser visto na documentação oficial.
#criando a função fpreproc a fim de avaliar o peso de cada categoria
def fpreproc(dtrain):
ratio = float((dtrain.values== 0).sum() / (dtrain.values == 1).sum())
return (print("Ajuste o hyper parametro scale_pos_weight para {}". format(ratio)))
fpreproc(y_train)o output dessa função é:
Ajuste o hyper parametro scale_pos_weight para 5.187141004261627
Agora com o peso definido, iremos aplicar a técnica de validação cruzada a fim de obter uma otimização do dataset.
# Aplicando Validação Cruzada com K-Fold
from sklearn.model_selection import cross_val_score
xgb = XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=0.1, gamma=1,
learning_rate=0.05, max_delta_step=0, max_depth=5,
min_child_weight=1, missing=None, n_estimators=500, n_jobs=1,
nthread=None, objective='binary:logistic', random_state=42,
reg_alpha=0, reg_lambda=1, scale_pos_weight=5.187141004261627, seed=None,
silent=None, subsample=0.9, verbosity=1)
# Gerando uma lista com os resultados para compararmos
scores = cross_val_score(xgb, X_train, y_train, cv=10, scoring='roc_auc', n_jobs=-1)
print("Scores = ", scores)
print("ROC_AUC = {:.3%}\n". format(scores.mean()))
# Fit do modelo
xgb.fit(X_train, y_train, eval_metric='auc')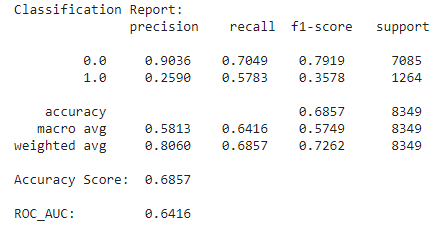
Em comparação ao modelo de Random Forest, podemos comparar quais variáveis tiverem mais influência no modelo XGBoost.
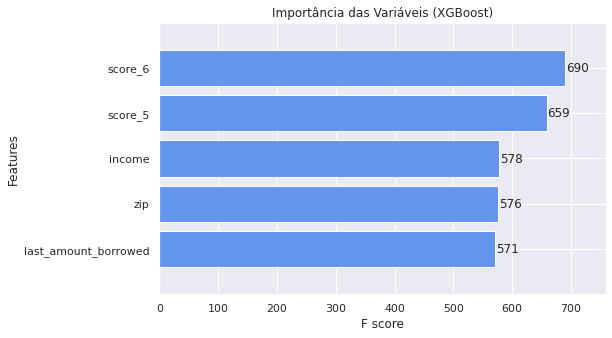
3. Otimização do Modelo
Nos próximos passos utilizei o modelo XGBoost Classifier e executei algumas rotinas de otimização dos hiper parâmetros.
Há de se observar que o modelo utilizando o XGBoost deu mais peso para as variáveis Score_6e Score_5. Já o modelo RandomForest utilizou as variáveis Income e application_time_in_funnel.
3.1 Bayes Search
Scikit-Optimize é uma biblioteca Python de código aberto que fornece uma implementação de Otimização Bayesiana que pode ser usada para ajustar os hiper parâmetros de modelos de Machine Learning da biblioteca Python Scikit-Learn.
Em contraste com GridSearchCV, nem todos os valores de parâmetro são testados, mas em vez disso, um número fixo de configurações de parâmetros é amostrado a partir do especificado distribuições. A abordagem bayesiana rastreia os resultados de avaliação anteriores que são usados para formar um modelo probabilístico que mapeia hiper parâmetros para as probabilidades de pontuação da função objetivo.
O Bayes Search é a automação para tunning dos hiper parâmetros. É uma biblioteca relativamente nova que está em desenvolvimento e que facilita a nossa busca no refinamento dos hiper parâmetros.
# 1. importar as bibliotecas necessárias
import skopt
from skopt import BayesSearchCV
from sklearn.model_selection import StratifiedKFold
#2. Definir intervalos de otimziação
bayes = BayesSearchCV(
estimator = XGBClassifier(
n_jobs = 1,
eval_metric = 'auc',
silent=1,
tree_method='exact',
booster='gbtree',
objective='binary:logistic',
sampling_method='uniform',
scale_pos_weight=5.187141004261627
),
#2.1 Definindo intervalos de otimização
search_spaces = {
'learning_rate': (1e-5, 1.0, 'log-uniform'),
'max_depth': (1, 5),
'max_delta_step': (0, 20),
'reg_alpha': (.001, 15.0),
'reg_lambda': (.001, 15.0),
'subsample': (0.01, 1.0, 'uniform'),
'colsample_bytree': (0.01, 1.0, 'uniform'),
'gamma': (1e-4, 0.5, 'log-uniform'),
'n_estimators': (50, 500),
},
#2. definindo método de avaliação
scoring = 'roc_auc',
cv = StratifiedKFold(
n_splits=10,
shuffle=True,
random_state=42
),
n_jobs = 3,
n_iter = 6,
verbose = 0,
refit = True,
random_state = 42
)
# callback handler
def status_print_bayes(optim_result):
bayes_resultado = bayes.best_score_
print("Melhor resultado: {:.3%}".format( np.round(bayes_resultado,4)))
if bayes_resultado >= 0.98:
print('Suficiente!')
return True#3.2 Variação dos Hiper parâmetros
Neste momento, utilizando-se do matplotlib foi elaborado um gráfico para visualizarmos a variação dos hiper parâmetros em função das etapas de otimização e aprendizado:
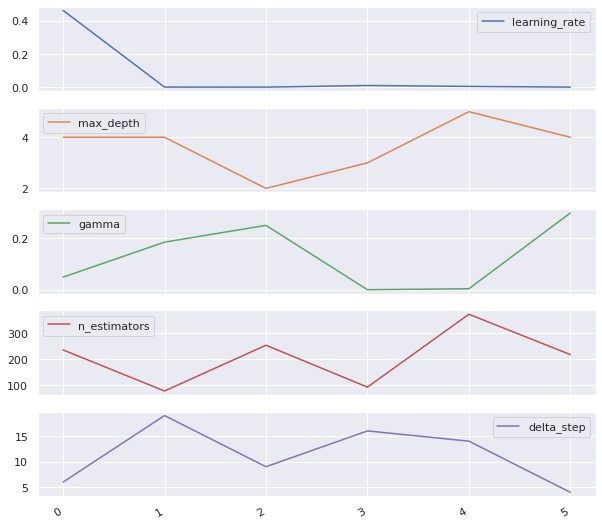
Com o modelo otimizado podemos verificar e comparar as métricas de avaliação.
3.3 Métricas de Avaliação
Conforme explanado no post elaborado por Jason Brownlee para classificação de modelos desbalanceados, estamos tratando de um modelo de probabilidades, onde ambas as classes são importantes:

Por esse motivo defini a métrica ROC AUC para verificar o desempenho do modelo otimizado.
Ainda da documentação oficial do XGBoost há recomendação para utilizarmos da métrica AUC para dataset desbalanceados, entre outros possíveis ajustes de hyper parâmetros.
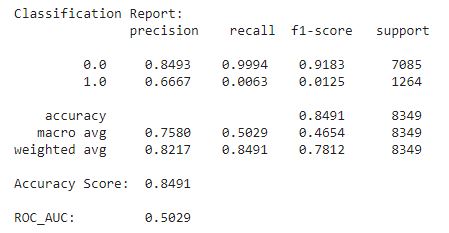
e a curva ROC, com o respectivos AUC
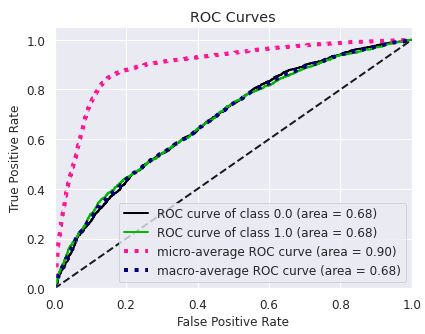
Antes de realizar o ajuste do hyper parâmentro para lidar com o desbalanceamento do dataset, o modelo estava resultando em overfitting, isso é, obtinha um resultado melhor durante o treinamento do que a previsão dos valores (praticamente decorando os resultados) ou mesmo se compararmos com os resultados iniciais sem ajustes observei a perda eficiência. O modelo otimizado era muito bom em prever quando não ocorria o default, porém o nível de acerto para 1 era extremamente baixo.
O modelo XGBoost é mais sensível a overfitting se os dados apresentarem ruído e o treinamento geralmente leva mais tempo devido ao fato de que as árvores são construídas sequencialmente.
GradientBoostMethods são difíceis de ajustar, pois normalmente existem três parâmetros: número de árvores, profundidade das árvores e taxa de aprendizagem sendo que cada árvore construída é geralmente rasa, porém apresentam ampla customização dos hyper parâmetros. Após consulta a documentação oficial, observei que poderia ajustar o parâmetro scale_pos_weight para o valor 5.1871 (conforme demonstrado nos passos anteriores), permitindo assim um ajuste adequado aos dados disponíveis durante o treinamento do modelo e obtenção de resultados mais adequados.
O princípio geral é que queremos um modelo simples e preditivo. A compensação entre os dois também é conhecida como compensação de viés-variância ou bias-variance tradeoff.
Do site oficial do XGBoost temos ainda sobre o viés-variância:
"Quando permitimos que o modelo fique mais complicado (por exemplo, mais profundidade), o modelo tem melhor capacidade para ajustar os dados de treinamento, resultando em um modelo menos tendencioso. No entanto, esse modelo complicado requer mais dados para se ajustar.
A maioria dos parâmetros no XGBoost são sobre compensação de variação de polarização. O melhor modelo deve negociar a complexidade do modelo com seu poder preditivo com cuidado. A documentação de parâmetros dirá se cada parâmetro tornará o modelo mais conservador ou não. Isso pode ser usado para ajudá-lo a girar o botão entre o modelo complicado e o modelo simples."
4. Redes Neurais
Durante o desemvolvimento dos estudos, foi elaborado um modelo de rede neurais com 5 camadas, sendo que na primeira camada e na terceira camada teremos 80 neurons e na quinta camada 40 neurons, para prever o risco de default de um cliente. Vamos aos passos:
n_entradas = X_train_scaled.shape[1]
#1. Definindo o modelo e hyper parâmetros
keras_model = Sequential([
Dense(80, input_shape=(n_entradas, ), activation='relu'),
Dropout(0.2),
Dense(80, activation='relu'),
Dropout(0.2),
Dense(40, activation='relu'),
BatchNormalization(),
Dense(1, activation='sigmoid')
])Os resultados obtidos foram:
- ROC AUC: 0.528
- precisao: 0.163
- F1-Score: 0.261
Conclusão
Pode-se observar que mesmo com um dataset tratado, sem outliers ou valores ausentes, normalizado e com dados codificados não se trata de um problema trivial.
Além disso, nossos dados de amostra se mostraram insuficientes, pois nosso modelo não consegue detectar corretamente muitos casos de default e, em vez disso, classifica incorretamente casos onde não ocorreriam. Característica de um dataset desbalanceado.
Da documentação oficial do TensorFlow é possível extrair o seguinte trecho:
"A classificação de dados desbalanceados é uma tarefa inerentemente difícil, pois há tão poucos exemplos para aprender. Devemos sempre começar com os dados primeiro e fazer o seu melhor para coletar o maior número possível de amostras e pensar bastante sobre quais recursos podem ser relevantes para que o modelo possa obter o máximo de sua classe minoritária. Em algum ponto, o modelo pode ter dificuldades para melhorar e produzir os resultados desejados, portanto, é importante ter em mente o contexto do seu problema e as compensações entre os diferentes tipos de erros."
Imagine que um modelo deste poderia elevar em muito as provisões utilizadas pelo banco para cobrir casos em que o cliente não cumpre com suas obrigações financeiras, elevando assim o custo de capital da instituição patrocinadora Nubank e consequentemente a taxa de juros a ser cobrada em cada empréstimo do cliente final.
Conforme foi possível obsevar durante o desenvolvimento dos modelos algumas variáveis possuem mais ou menos peso em determinado modelo, porém as métricas que influenciam os modelos aqui desenvolvidos, com os dados disponíveis são: income e score_ de crédito.
Grandes empresas de crédito implementam áreas robustas para desenvolver modelos e ajustá-los conforme crescimento da base de dados. Esse é um campo muito fértil e financeiramente viável de estudos relacionados a Data Science e Machine Learning.