
Ensemble
Por que usar apenas um modelo de machine learning, por que apenas uma forma de fazer previsão? Imagine que você poderia aproveitar o melhor de cada mundo, usar os pontos fortes de cada modelo e seu estimador e até mesmo combiná-los entre si.
No notebook que elaborei é apenas uma introdução de um conceito conhecido como Métodos de Ensemble, já que a documentação é vasta e não caberia apenas em um post.
A documentação original sobre a metodologia pode ser consultada neste link.
Me inspirei no post do Marcelo Randolfo para elaborar esse notebook, porém no post originial ele utiliza a base de dados da competição do Kaggle sobre sobreviventes ao naufrágio do Titanic.
O dataset
Como desafio pessoal, preferi utilizar outro dataset no meu exemplo. Os dados aqui foi retirado da UC Irvine Machine Learning Repository e representa uma abordagem baseada em dados para prever o sucesso do campanha de marketing de um banco Português.

A página com maiores informações sobre os dados pode ser acessada aqui.
O dataset é composto por 17 variáveis (colunas) e 45.211 entradas (linhas).
Na primeira parte do notebook esclareço como importá-lo diretamente do site para um dataframe e começá-lo a usar de pronto.
Na sequência são executados os comandos para conversão das variáveis categóricas a fim de utilizá-las nos demais modelos. Para entender mais sobre conversões de variáveis consulte aqui
Ensemble
Você entenderá a importância do método de Ensemble ao entrar no universo do Machine Learning e ficar perdido com a quantidade de modelos diferentes que temos a disposição. Temos regressão linear, polinomial e logística, gradiente descendente, XGBoost, máquina de vetores de suporte, naive bayes, árvores de decisão, Random Forest, entre outros.
Observe abaixo o resultado do classificador de votação para os diferentes modelos. No caso, o VotingClassifier fez a combinação dos modelos.
No notebook também são apresentados brevemente cada modelo de machine learning que foi utilizado para fazer a previsão.
Deixarei no post o detalhamento utilizado da método:
# 1. escolher e importar um modelo
from sklearn.linear_model import SGDClassifier
from xgboost import XGBClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import VotingClassifier
# 2. Instanciar e escolher os hyperparameters
model_xgbc = XGBClassifier()
model_sgd = SGDClassifier()
model_svc = SVC()
model_dt = DecisionTreeClassifier()
voting_clf = VotingClassifier(estimators=[('xgbc', model_xgbc), ('sgd', model_sgd),('svc', model_svc),('dt', model_dt)])
# 3. Separar os dados entre feature matrix e target vector
# os dados já foram separados anteriormente
# 3.1 Dividir o dataset entre treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 3.2 Padronizar os dados
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 4. Fit do modelo (treinar)
for model in (model_xgbc, model_sgd, model_svc, model_dt, voting_clf):
model.fit(X_train_scaled, y_train)
# 5. Fazer previsões em cima de novos dados
model = []
accuracy = []
for clf in (model_xgbc, model_sgd, model_svc, model_dt, voting_clf):
y_pred = clf.predict(X_test_scaled)
model.append(clf.__class__.__name__)
accuracy.append(accuracy_score(y_test,y_pred))
# Verificar a acurácia
col = ['Acurácia']
ac = pd.DataFrame(data=accuracy, index = model, columns=col)
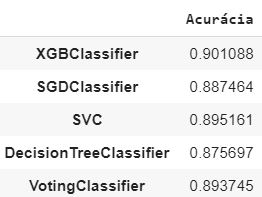
acA partir do modelo acima os resultados de acurácia obtidos foram:
Ainda podemos gerar o report para avaliarmos o modelo obtido:
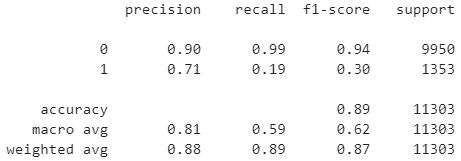
Do report anterior podemos verificar que o nosso modelo acertou 90% das previsões onde a resposta a campanha de marketing foi negativa e acertou 71% das vezes onde foi positiva.
Para saber mais sobre as métricas de classificação e avaliação de modelos pode acessar meu post sobre o assunto.
Conclusão
No nosso modelo em questão, a Acurácia nos mostra que 89% das vezes em que o modelo previu sim ou não estava correto.
Mesmo cometendo erros, o classificador geralmente consegue performar melhor do que os estimadores individualmente. De acordo com Aurélien Géron:,
Mesmo que cada estimador seja um aprendiz fraco (o que significa que sua classificação é apenas um pouco melhor do que adivinhações aleatórias), o conjunto ainda pode ser um forte aprendiz (alcançando alta acurácia).
Para o nosso exemplo, o modelo XGBoost é o que performa melhor entre os modelos individuais, mas ainda assim é uma performance próxima ao classificador de votação.
Data Science na Prática
O material aqui desenvolvido é parte da provocação feita no curso de Data Science na Prática onde fui desafiado a tentar explicar os passos e ferramentas aplicadas durante a evolução do material. Todo o material a ser desenvolvido no curso será centralizado no GitHub.