
Machine Learning Deploy
Desenvolvimento de um modelo de Machine Learning
Nesse post irei abordar os passos necessários para disponibilizar uma API que faz a previsão do valor de imóveis treinada com Machine Learning. Ao final da leitura você irá ver quais são os passos necessários para completar esta etapa.
Por que aproximadamente 90% dos modelos de Machine Learning não evoluem de um trabalho acadêmico ou de um notebook no Google Colab para um modelo online que alimente outras aplicações?
Uma das respostas para a pergunta inicial é que a maioria das organizações ainda não estão familiarizadas com a tecnologia e ferramentas similares, muito menos possuem hardware necessários para tal, como GPU´s e ambientes em nuvem.
Outra resposta seria a desconexão entre profissionais de TI e cientistas de dados e engenheiros de Machine Learning. Profissionais de TI tendem a prover um ambiente estável e confiável, em contra partida profissionais que lidam com Machine Learning focam em iterações e experimentação.
Um artigo muito interessante sobre a dificuldade desta etapa pode ser visto no post.
Voltando ao tema desse post a imagem a seguir demonstra o ciclo de vida de um projeto completo. É possivel obsevar que uma das etapas necessárias é o deploy do modelo. Por isso precisamos entender também quais são os passos necessários para realizar essa etapa.
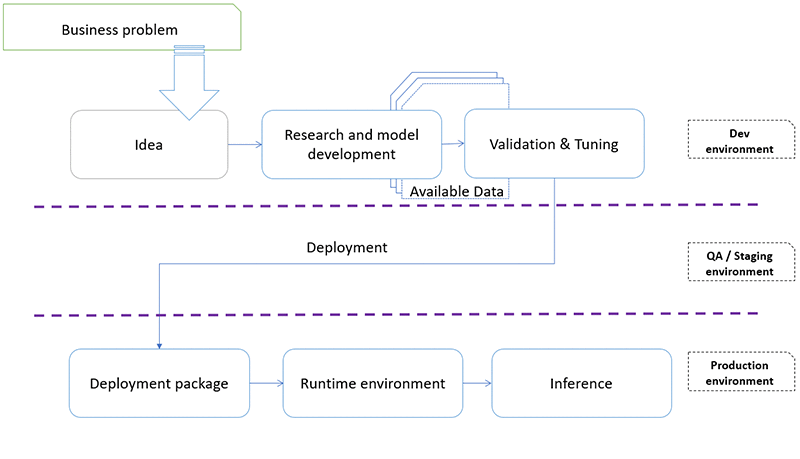
Irei abordar nesse post como preparar o ambiente Windows para desenvolvimento de software, ilustrar brevemente o modelo de Machine Learning criado e de forma mais abrangente a sequência para que esse modelo não fique limitado somente ao seu computador, mas que fique disponível para acesso online.
Todo o conteúdo desenvolvido está sincronizado com o repositório desse projeto. Deixo aqui me reconhecimento e agradecimento ao curso que provocou esse post. Mais sobre o curso pode ser visto em: https://sigmoidal.ai.
1. Preparação do ambiente
Em um ponto ou outro quando trabalhamos com desenvolvimento de software acabamos por nos deparar com ambientes virtuais. Essa é uma boa prática e altamente recomendável.
Desenvolver um aplicativo limita você a uma versão específica da linguagem e das bibliotecas que utilizou para o desenvolvimento, instalados em seu sistema operacional. Tentar executar todos os aplicativos em uma única instalação torna provável que ocorram conflitos de versões entre coleções de bibliotecas. Também é possível que mudanças no sistema operacional quebrem outros recursos de desenvolvimento que dependem dele.
O ambiente virtual, ou virtualenv são instalações leves e independentes, projetadas para serem configuradas com o mínimo de confusão e “simplesmente funcionar” sem exigir configuração extensiva ou conhecimento especializado.
O virtualenv evita a necessidade de instalar pacotes globalmente. Quando um virtualenv está ativo, em Python por exemplo, o pip instala pacotes no ambiente, o que não afeta a instalação base do Python que foi realizada no sistema operacional de forma alguma.
O Plano
O nosso plano será preparar um ambiente windows de desenvolvimento, para criarmos um modelo de Machine Learning, a partir de um notebook criado no ambiente virtual de forma a receber novas consultas no formato json e retornar um valor de previsão de venda para um imóvel em São Paulo.
A partir do notebook iremos exportar o modelo de Machine Learning. Com o Insomnia iremos certificar que a API está recebendo corretamente os dados e retornando o valor desejado. Com a confirmação do teste, iremos exportar a API para o ambiente web utilizando o Heroku a fim de disponibilizarmos para consultas na online de forma independente do ambiente virtual que fizemos o desenvolvimento.
Instalação do Python
Após diversas tentativas com erros e acertos acabei esbarrando em um tutorial que me auxiliou muito durante esse processo:
Para alguns pode complicar um pouco, pois o tutorial está em inglês, porém a boa notícia que é um vídeo então fica fácil de acompanhar as etapas corretas de instalação:
O vídeo pode ser acessado diretamente neste link, vou reproduzir aqui algumas anotações que fiz:
-
Durante a instalação não adicione o python ao PATH do windows. A princípio pode ser um incômodo toda vez que for utilizar o comando python para iniciar uma aplicação será necessário digitar o caminho completo, por exemplo:
c:\python\386\pythonmas repare que dessa forma vc é capaz de escolher qual versão do python desejará utilizar e se você manter o padrão aos selecionar a pasta de instalação poderá ter mais de um versão em seu computador, sem comprometer o que já havia sido criado. -
Com o python instalado, a partir da versão 3.3, já é possível criar prontamente um ambiente virtual, pois já possui com as bibliotecas necessárias. Para tanto no terminal do windows (tecla windows + r -> digite cmd.exe e tecle enter), acesse a pasta onde deseja criar o seu projeto. Aqui fica mais uma dica para que você crie uma pasta de projetos no seu hd, por exemplo:
c:\pyprojetopara acessar a pasta digitecd\pyprojeto, uma vez dentro da pasta entre com o seguinte comando para criar o ambiente virtualc:\pasta_de_instalação_python\python -m venv nome_projetosubstituindo pasta_de_instalação_python pelo caminho onde seu python foi instalado e no lugar de nome_projeto o nome do seu projeto, para mim ficou:c:\python\386\python -m venv imovsp. Aguarde um tempo, pois seu projeto estará em criação. -
Após a criação do ambiente virtual será necessário ativá-lo, para isso entre com o comando:
nome_projeto\Scripts\activate, mais uma vez será necessário substituir name_projeto pelo nome que você deu ao seu projeto, no meu caso ficou assim:imovsp\Scripts\activate. Você poderá observar na linha de comando que o nome do projeto estará entre parênteses(imvosp) c:\pyprojeto\imovspisso significa que o ambiente virtual está ativado e as bibliotecas que futuramente forem instaladas utilizando o comando pip, por exemplo:pip install pandas numpyficarão restritas a esse ambiente. -
Caso você esteja refazendo esses passos e seja necessário instalar alguma das bibliotecas basta repetir o comando
pip install biblioteca_desejada, por exemplo adiante iremos utilizar o flask e algumas bibliotecas, para instalar eu utilizeipip install flask-restful flask gunicorn. -
Aproveito para utilizar o gancho aqui, que ao final do desenvolvimento iremos utilizar o comando
pip freeze > requirements.txta fim de exportar um lista com todas as bibliotecas que utilizamos durante o desenvolvimento. -
No ambiente virtual o python poderá ser acionado diretamente com
python, após o enter você verá o prompt inciaindo com »>. Para desativar o ambiente virtual basta entrar com o comandodeactivate.
Visual Studio Code ou VSCode
Largamente utilizado por desenvolvedores o VSCode é a IDE da Microsoft com uma série de facilidades embutidas.
Todas as etapas que vimos no passo 1.1 podem se feitas diretamente no VSCode. Como há muitas referências para configuração do ambiente na web e a própria documentação desenvolvida pela MS é ampla, vou passar apenas pelos pontos que tive dificuldade.
Vale ressaltar que a principal facilidade do VSCode é trabalhar com diversas extensões, criando uma infinidade de facilidades. Se você ainda não o utilizou após as atualizações em 2019 vale conhecê-lo ou mesmo se você utiliza outras IDE´s vai ficar impressionado com as facilidades de importação de todas as configuração para a nova IDE.
Em relação as dificuldades encontradas posso destacar principalmente a minha falta de experiência para lidar com o software me si, apesar da minha vontade em aprender programação e disciplinas ligadas a inteligência artificial, estava muito acostumado com o ambiente do Google Colab. Sair da zona de conforto nos possibilita novos aprendizados e favorece o nosso desenvolvimento.
Novamente apoiei em um dos vídeos do Corey Schafer Setting up a Python Development Environment, o vídeo possui mais de uma 1hora de gravação, bem extenso passando por diversas possibilidades com muito detalhes e dicas, vale muito a pena para evitar algumas dores de cabeça.
GitHub
Outra facilidade do VScode é a integração nativa com o GitHub, basta clicar no ícone correspondente:

Antes de clicar e iniciar um novo repositório, crie na raiz do seu projeto um arquivo .gitignore . Esse arquivo irá apontar para a plataforma quais arquivos deverão ser ignorados durante o versionamento e sincronização da sua aplicação, como sugestão indico o site:
GitIgnore IO, basta apontar qual linguagem você está desenvolvendo a sua aplicação que ele irá gerar automaticamente o arquivo. Após isso basta copiar o texto gerado para o arquivo no seu ambiente de desenvolvimento.
Lembre-se de acrescentar também, em qualquer lugar:
.vscode(para evitar a sincronização da sua configuração do VSCode local)[sS]cripts/(para evitar o envio dos scripts de criação do ambiente virtual)
Se quiser ver o meu, pode consultá-lo em .gitignore
Após salvar arquivo você já está pronto para realizar a integração com o GitHub, basta clicar no ícone correspondente e criar o repositório.
Após estes passos nosso ambiente está pronto para desenvolvimento. Espero ter ajudado com esses passos, pois são muitas informações disponíveis que muitas vezes apenas confundem mais. Caso tenha ainda alguma dúvida entre em contato.
2. Notebook
O notebook desenvolvido pode ser acessado no link notebook
O objetivo desse post são os passos necessários para o deploy de uma aplicação com base em Machine Learning, a etapa de análise exploratória de dados foi propositalmente suprimida.
notebook irei treinar um modelo para fazer a previsão do preço de venda para imóveis em São Paulo, entretanto o objetivo final é fazer o deploy de um modelo para fazer a alimentação de uma aplicação web.
Os dados utilizados foram obtidos no link e os dados foram tratados pelo Carlos Melo.
Entretanto irei demonstrar como exportar o modelo treinado e as variáveis utilizadas, para que possam ser utilizados em uma aplicação web.
Salvado o modelo
Após importar os dados, tratá-los e treinar o modelo, se você quiser que uma aplicação web utilize esse conhecimento será necessário exportá-lo, para tanto utilize o comando:
from joblib import dump, load
dump(model, 'model\\model.joblib')o comando irá exportar o modelo criado com o instância model e salvá-lo na pasta model com o nome e extensão model.joblib.
Entratanto para utilizá-lo será necessário exportar também as features (variáveis) utilizadas durante o aprendizado, para tanto utilize:
# salvando os nomes das features
features = X_train.columns.values
dump (features, 'model\\features.names')novamente você irá salvar as features na pasta model com o nome e extensão features.name. Observe que na primeira linha do bloco anterior criamos uma variável ( features ) a fim de receber os nomes das colunas da matriz de variáveis (feature matrix).
Após exportarmos o modelo podemos importá-lo para verificar se tudo está correto.
#importando o modelo
novo_modelo = load('model\\model.joblib')
#verificando o tipo
type(novo_modelo)Do bloco anterior obtemos o output: sklearn.ensemble._forest. RandomForestRegressor
3. Cirando a API com Flask
Com nosso modelo pronto e salvo, é hora de criarmos a API utilizando o framework Flask.
A documentação sobre o Flask pode ser acessada aqui.
Iremos criar um arquivo com o nome app.py a fim de instanciar o framework, carregar o modelo (exportado do passo anterior), uma classe com a definição de GET e POST e iremos acrescentar tudo a API.
# importando bibliotecas necessárias
import numpy as np
from flask import Flask, jsonify, request
from flask_restful import Api, Resource
from joblib import load
# instanciando objeto Flask
app = Flask(__name__)
# API
api = Api(app)
# carregar modelo
model = load('model/model.joblib')
class PrecoImoveis(Resource):
def get(self):
"""
retorna as informações iniciais da API
"""
return {'Nome': 'Marcel Bittar', 'web': 'http://mabittar.github.io'}
def post(self):
"""
recebe todos os argumentos que estão sendo enviados para a aplicação
valor com base no modelo.joblib elaborado
permitido apenas uma consulta por vez
var input_values recebe uma matriz reformatada para utilizar no sklearn
var predict faz a previsão de valor calculado utilizando o modelo criado anteriormente com os valores fornecidos pela input_values retornando apenas o primeiro valor
retorna um json da previsão de valor do imóvel
"""
args = request.get_json(force=True)
input_values = np.asarray(list(args.values())).reshape(1, -1)
predict = model.predict(input_values)[0]
return jsonify({'Previsao do valor R$ ': float(predict)})
api.add_resource(PrecoImoveis, '/')
if __name__ == '__main__':
app.run()Com o arquivo pronto, iremos executá-lo usando o terminal do VSCode: python app.py
Caso o arquivo esteja correto o terminal irá retornar que a API está funcionando no link http://127.0.0.1:5000/ esse link significa que temos um aplicação rodando localmente na máquina e que pode ser acessada pelo navegador web. Para tanto basta copiar e colocar o link no navegador que você utiliza.
Caso seja necessário interromper o aplicativo, clique na janela do terminal e entre com as teclas CRTL+C e a aplicação será finalizada.
4. Insomnia
documentação oficial para utilização do Insomnia.
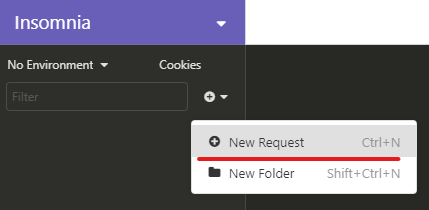
Criando um New Request
Para realizar a requisição precisamos habilitar o Insomina para que consiga acessar a url que o Flask nos forneceu anteriormente
Criando um GET
Aqui devemos nomear nossa requisição (GET). Fique à vontade para escolher, pois esse é apenas um ambiente de testes

O próximo passo é apontar o Insomnia para o link que o flask nos deu:

Após informar a URL da API basta clicar no botão send. Lembre-se que durante a criação da API em flask definimos um posição para GET, no meu caso utilizei meu nome e meu contato. Após acionar o botão get você deverá estar vendo essa informação na tela para certificar que a API está em funcionamento, caso não tenh visto a mensagem retorne na IDE, para mim era o VSCode e veja no painel de terminal se há algum erro.
Na primeira vez eu havia posicionado o : em local errado e a API não estava funcionando. Foi necessário interromper o funcionamento, alterar o arquivo, salvar e iniciá-lo novamente.
Criando um POST
Agora que temos certeza que a API está funcionando vamos criar uma requisição do tipo POST para testar o modelo preditivo.
Para testar o modelo é necessário se lembrar de preencher todas as colunas (features) do modelo, para tanto deixei um arquivo .txt com as informações necessárias:
Será necessário criar uma requisição, porém agora do tipo PSOT, após inserir os valores no painel do Insomnia, clique em SEND. a API deverá retornar o valor previsto para o imóvel de acordo com as características que você inseriu.
Caso não tenha resposta ou ocorra algum erro retorne novamente para o terminal e verifique se está apontado algum erro. Caso seja necessário corrigir algo lembre-se de interromper a API, editar o arquivo, salvar e iniciar novamente, para então clicar no botão SEND.
Na imagem a seguir é possível ver a API retornando com o valor previsto para o imóvel com as características desejadas.
5. Heroku
Os passos para enviar a API testada para o Heroku são:
Criando um Web App
Conforme documentação oficial do Heroku para Deploy de App com Gunicorn o primeiro passo é criarmos um servidor HTTP para atender aos requests. O Gunicorn é um servidor HTTP em python desenvolvido para atender entre outros aplicações WSGI. Ele permite rodar qualquer aplicação desenvolvida em Python rodando diversos processos em um simples Dyno.
Para adicionarmos o gunicorn a nossa aplicação é necessário seguir as etapas:
Criar um arquivo “procfile”
Neste passo é necessário que você tenha o gunicorn instalado. Caso seja necessário use pip install gunicorn .
Na sequência edite o procfile criado e insira simplesmente web: gunicorn app:app .
Feito isso basta salvar o arquivo e fechá-lo.
Exportando as bibliotecas utilizadas
Novamente no terminal do VSCode entre com o comando pip3 freeze > requirements.txt .
Você irá reparar que foi criado um arquivo requirements.txt onde estão listadas todas as bibliotecas utilizadas no desenvolvimento da aplicação, desde a versão do python utilizada e as bibliotecas instaladas pelo VSCode.
Upload da aplicação para o Heroku
Finalmente iremos iniciar a última etapa do deploy da aplicação. A documentação oficial pode ser consultada aqui
Volte ao terminal do VSCode e insira os comandos:
git init para iniciar o repositório local de arquivos (esse comando já foi utilizado anteriormente, porém de forma automática quando foi feita a sincronia com o repositório na web ou GitHub).
heroku login nesse momento irá aparecer um pop-up para você logar na sua conta do Heroku, caso ainda não tenha se cadastrado esse é o momento.
heroku create nomedasuaapp substitua o nomedasuaapp pelo nome do seu aplicativo
git add . esse é o passo para preparar todos os arquivos a serem commitados e enviados aos Heroku
git commit -m "Text do Commit" substitua Text do Commit para um texto de controle de versões, que seja fácil de você lembrar quais foram as alterações realizadas por exemplo first commit lembre-se de manter as aspas, pois faz parte da sintaxe.
heroku git:remote -a nomedasuaapp substitua o nomedasuaapp pelo nome do seu aplicativo informado anteriormente
git push heroku master esse será o passo para upload da sua aplicação. Aguarde o envio dos arquivos e na sequência acompanhe a montagem (build) do seu aplicativo.
Durante o upload dos arquivos utilizando o git push tive diversas dificuldades, pois algumas bibliotecas que eu havia utilizado para desenvolvimento não estavam disponíveis no Heroku, mas com um olhar mais atento pude perceber que tais bibliotecas foram instaladas pelo VSCode e não iriam interferir com o funcionamento do modelo desenvolvido. Para tanto alterei no arquivo requirements.txt as versões das bibliotecas que eu utilizei com as que estavam disponíveis no momento em que eu fiz o deploy no Heroku. Na mesma linha de comando que você acompanha o envio dos arquivos para a web será possível observar quais as versões das bibliotecas que estão disponíveis. Tal erro vai aparecer após o envio dos arquivos, quando o Heroky estiver montando a aplicação.
Apenas como exemplo, quando eu criei o documento requirements.txt estava com a biblioteca pylint na versão 3.3, porém o Heroku possuía apenas a versão 2.6.0, bastou alterar manualmente no arquivo e realizar os passos que esse erro foi superado.
Conclusão
Após todas as etapas nosso modelo de Machine Learning está funcionando na nuvem, agora é possível substituir no Insomnia a url antiga http://127.0.0.1/ pela url fornecida pelo Heroku.
Você pode consultar meu app em: https://imovsp.herokuapp.com/. Usando o Insomnia é possível fazer um post (pode usar o exemplo das features do arquivo valores usados) e fazer um previsão de preço do imóvel que deseja consultar.
Como visto é um trabalho extenso e acaba envolvendo parte de desenvolvimento web, requisições para servidores e etc. Esses temas acabam fugindo da área de conhecimento da ciência de dados.
Implantar Machine Learning em empresas é e continuará sendo difícil, e isso é apenas uma realidade com a qual as organizações precisarão lidar. Felizmente, algumas novas arquiteturas e produtos estão ajudando os cientistas de dados. Além disso, à medida que mais empresas estão escalando as operações de ciência de dados, elas também implementam ferramentas que tornam a implantação do modelo mais fácil.
Apesar de tudo a cadeia de Machine Learning ainda está em seus estágios iniciais. Na verdade, os componentes de software e hardware estão em constante evolução para atender às demandas atuais do ML. Docker / Kubernetes e arquitetura de microsserviços podem ser empregados para resolver os desafios de heterogeneidade e infraestrutura. As ferramentas existentes podem resolver muito alguns problemas individualmente.
Em empresas internacionais acredito que reunir todas essas ferramentas para operacionalizar o ML é o maior desafio hoje, porém em empresas nacionais continua sendo a questão de aquisição e tratamento de dados, portanto ainda estamos engatinhando no processo.