
Machine Learning Usando FastAPI
Uma API assíncrona em FastAPI para disponibilizar um Modelo de Machine Learning
A ideia original desse post é criar um série de post com um material em português que ensine como criar uma API assíncrona, escalável e robusta utilizando o FastAPI, mas não é qualquer API, iriei demonstrar como utilizei recursos avançados do FastAPI e outras bibliotecas para tornar um projeto robusto com pinta profissional. Eu utilizei como exemplo uma API onde é possível consumir um modelo de Machine Learning que prevê se texto é spam ou não.
Nesse post não vou entrar em detalhes como criar, ativar um ambiente virtual em Python, ou mesmo como instalar as dependências necessárias para o projeto para deixá-lo um pouco mais curto. Caso tenham alguma dúvida em relação a esses pontos e boas práticas entrem em contato que posso pensar em algo diferente para os próximos posts.
O projeto pode ser clonado diretamente do meu repositório.
O que diferencia meu projeto
Algumas características dos projeto:
- rotas (endpoints) de acesso para cadastro e autenticação do usuário.
- somente com o usuário autenticado é possível utilizar a rota para acesso ao modelo de machine learning.
- rotas documentas automaticamente e interativas
- middleware que computa o tempo entre a entrada da request e saída da response.
- logs configurados para facilitar o debug da API mesmo em ambiente de produção
- estrutura reutilizável, utilizando orientação a objetos.
- arquivo de configuração de ambiente utilizando recursos do pydantic settings.
- a API e a conexão com o banco de dados possuem recursos assíncronos, utilizando a versão 1.4 do SQLAlchemy.
- as tabelas e suas respectivas atualizações podem ser criadas diretamente com o Alembic já utilizando configurações e updates assíncronos.
- utilizando o docker-compose é possível carregar a API e o banco de dados em containers locais.
- na API existem alguns endpoints para monitoramento, health-check, inclusive com validação da conexão com o banco de dados.
- cada usuário possui 10 utilizações disponível por mês.
Mãos a massa!!!!
O que é o FastAPI
FastAPI é um framework em Python que possui diversas ferramentas prontas para permitir desenvolvedores a utilizar uma interface REST para chamar funções utilizadas na criação de aplicativos. Neste exemplo, o autor usa FastAPI para criar contas, fazer login, autenticar e disponibilizar um modelo de machine learning.
Configurações iniciais
Após instalar as dependências será necessário criar um arquivo com as variáveis de ambiente. Um arquivo .env . Já deixei pronta a lista de variáveis necessárias, basta copiá-las e escrever os valores desejados na frente de cada uma. Mas nesse post, deixarei um pouco mais de detalhes.
APP_ENV=local # a ideia aqui é permitir que o código possa ser enviado para um ambiente de produção
PROJECT_NAME="Spam Predictor with FastAPI" # dê o nome para o seu projeto
POSTGRES_USER=postgres_user # exemplo usuário para conexão no banco de dados.
POSTGRES_PASSWORD=example # exemplo de senha para acesso ao banco de dados
POSTGRES_SERVER=localhost # exemplo de endereço para conexão ao banco dados
POSTGRES_PORT=5432 # porta padrão de acesso ao postgres
POSTGRES_DB=spam_ml # exemplo de database referente ao seu projeto
JWT_SECRET= # veja instruções como gerar seu secret
LOCAL_PORT=8000 # porta onde a API será disponibilizada
FIRST_SUPERUSER=first_user # exemplo de nome do primeiro usuário do banco de dados
FIRST_SUPERUSER_PASSWORD=123456 # exemplo de senha para acesso ao primeiro usuário
FIRST_SUPERUSER_EMAIL=first_user@yopmail.com # # exemplo de email para o primeiro usuário
LOG_LEVEL=DEBUG # nível de log para desenvolvimento e debug em ambiente local
WORKERS_PER_CORE=1 # configurações do uvicorn
MAX_WORKERS=1 # configurações do uvicornPara gerar um Token JWT out JWT_SECRET, execute na linha de comando:
openssl rand -hex 32Será gerado algo como: b59cbee90cd294bf5e1b66fcd8a57fe8ce6999c2e0fa88304ff8c87766329937
Mais uma vez lembrando que esse é um arquivo com as variáveis de ambientes, isso permite configurações diferentes para diversos ambientes. Por exemplo, em um ambiente de produção é possível apontar para um banco de dados na nuvem ou mesmo utilizar uma porta local diferente do exemplo. Ajustar o nível dos logs e etc….
Abusando do PydanticSettings
Já que estamos falando das variáveis de ambiente vale comentar sobre o arquivo app/settings.py esse arquivo herda do pydantic a classe BaseSettings. Esse herança permite especificar o arquivo de onde virá os valores para cada configuração necessária. Dentro da classe Settings observe que há outra classe Config com env_file = '.env' . Caso vc deseje alterar o nome do seu arquivo de de variáveis para, por exemplo, local.env basta alterar o valor que a variável env_file recebe para 'local.env'.
Dentro desse mesmo arquivo ainda é gerado o link completo para conexão com o banco de dados. A variável SQLALCHEMY_DATABASE_URI recebe um valor composto pela função PostgresDsn.build(), onde podemos definir diferentes parâmetros como esquema de conexão com o banco da dados, configurações de acesso e tamanho do cache.
O arquivo principal app.py
Uma vez configurado o ambiente é válido olhar para o arquivo app/app.py onde a mágica acontece, pois é o arquivo principal da nossa API.
Inicialmente as variáveis do arquivo settings.py são carregadas. Observe que nesse caso fiz questão de colocar o decorator @lru_cache(), pois como tratam de variáveis de ambiente, dificilmente serão modificadas e dessa forma o python se encarrega de buscar os valores diretamente do cache / memória e não mais do arquivo de texto criado anteriormente.
@lru_cache()
def get_settings():
return Settings()
settings = get_settings()O próximo passo é instanciar a classe FastAPI e definir a rota de acesso a documentação. aqui também vale alterar da forma como for necessária.
app = FastAPI(
title=settings.PROJECT_NAME,
docs_url=f"/docs/",
version="1.0.0",
)No próximo trecho de código são carregados os middlewares e as rotas de acesso.
Aqui uma preferência do autor, por carregá-las nos respectivos arquivos __init__.py e passá-las como uma lista ao arquivo principal, deixando o código mais limpo.
if len(middlewares_list) > 0:
for middleware in middlewares_list:
app.add_middleware(middleware)
if len(endpoints_list) > 0:
for endpoint in endpoints_list:
app.include_router(endpoint)O penúltimo trecho desse arquivos é onde definimos como a API irá lidar com os erros durante uma requisição, deixei genérico, mas também poderia ser customizado de acordo com a necessidade de cada negócio.
@app.exception_handler(HTTPError)
async def http_error_handler(request: Request, exception: HTTPError):
if exception.msg:
return JSONResponse(
status_code=exception.code,
content={exception.**repr**},
)
else:
str_tb = format_exc()
msg = ErrorMessage(
traceback=str_tb,
title="Some error occur",
code=exception.code
)
return JSONResponse(status_code=exception.code, content=msg.dict())Note que o decorator herda a classe HTTPError que poderia ser diretamente do FastAPI / Pydantic ou como no meu caso de urllib.error
O último trecho é um artifício para “startar” a API diretamente pelo arquivo, mas conforme foram sendo adicionados recursos acabou não sendo conveniente dessa forma.
if **name** == '**main**':
from uvicorn import run
run(app, # type: ignore
port=settings.PORT,
host=settings.HOST,
use_colors=True
)Esses parâmetros podem ser passados diretamente para a IDE em que você está desenvolvendo para permitir uma rápida iniciação do projeto.
O Banco de Dados
Conforme destacado anteriormente fiz questão de utilizar o SQLAlchemy na versão 1.4 para permitir o acesso ao banco de dados de forma assíncrona. Para essas configurações vamos olhar dentro da pasta app/database.
O arquivo app/database/session.py é responsável pela conexão e disponibilizar a sessão assíncrona com o Banco de Dados.
A engine do banco é criada na função:
engine = create_async_engine(
SQLALCHEMY_DATABASE_URI,
pool_pre_ping=True,
connect_args={"server_settings": {"jit": "off"}}
)Vale destacar que tive alguns problemas de conexão com o banco de dados Postgres de forma assíncrona e ao buscar uma solução na internet me deparei com esses connect_args={"server_settings": {"jit": "off"}}) . Foi a forma que eu encontrei para contornar a issue de conexão do esquema Asyncpg e uma coluna do tipo Enum.
Depois criado a engine do banco dados, vêm os comandos para disponibilizar a sessão:
session*local = sessionmaker(bind=engine, class*=AsyncSession, expire_on_commit=False, autoflush=True)
ScopedSession = scoped_session(session_local)
async def get_session() -> AsyncGenerator:
async with ScopedSession() as session:
yield sessionAinda dentro da pasta app/database vale uma olhada rápida no arquivo base_class.py. Ele será responsável por auxiliar o SQLAlchemy e o Alembic na criação das tabelas no nosso banco de dados.
@as_declarative()
class Base:
id: int = Column(Integer, primary_key=True, autoincrement=True)
**name**: str
# Generate __tablename__ automatically
@declared_attr
def __tablename__(cls) -> str:
return cls.__name__.lower()A representação em python dos modelos das tabelas do banco dados estão na pasta app/models. Essa representação se faz necessário para que o SQLAlchemy possa “traduzir e conversar” com o “dialeto” do Postgres.
Aqui também houve uma preferência do autor em mesclar o modelo do banco de dados com os schemas de cada endpoint. Em diversas literaturas, inclusive na documentação oficial você irá ver o schemas em uma pasta a parte no projeto. Mas preferi deixá-los em um mesmo arquivo, pois esse projeto não possui um alto nível de complexidade. Mais uma vez preferência minha.
No arquivo app/models/usermodel.py é possível ver onde eu fiz a presentação da tabela usermodel do banco de dados. Note que a classe UserModel herda da classe Base, lá da pasta app/database. Aqui me fiz valer de mais algumas facilidades do Pydantic como validação dos campos e deixar como exemplo para implementações futuras. Por exemplo, a validação do atributo fullname ou nome completo deve ter pelo menos Nome e Sobrenome. A ideia aqui é que seja passada uma string com pelo menos um espaço no meio. E a validação do documento informado no momento do cadastro, que em ambientes locais está desativado, mas alterado o valor da variável APP_ENV para “dev” por exemplo passa a ser necessário informar um CPF ou CNPJ que seja válido.
Um pouco mais abaixo é possível observar os schemas utilizados para validação das requisições e das respostas. Aqui é onde o Pydantic gera magicamente a documentação do OpenAPI.
python code:
class BaseUser(BaseModel):
email: EmailStr = Field(..., description="User email for contact")
full_name: FullNameField = Field(min_length=3)
document_number: str = Field(..., description="User document number")
@validator("full_name")
def validate_full_name(cls, v):
try:
first_name, last_name = v.split()
return v
except Exception:
raise HTTPException(status.HTTP_404_NOT_FOUND,
detail="You should provide at least 2 names")
@validator("document_number")
def validate_document_number(cls, v):
try:
logger.info(f"Validating document number {v}")
return parse_doc_number(v)
except Exception:
raise HTTPException(status.HTTP_404_NOT_FOUND,
detail="You should provide a valid document number")
class UserSignIn(BaseUser):
password: str = Field(min_length=6, description="User Password")
username: str = Field(..., min_length=3, description="Username to login") # role: Optional[str]
phone: Optional[str]
class Config:
orm_mode = True
class UserSignOut(BaseUser):
id: int
created_at: datetime # role: UserRole
phone: Optional[str]
username: str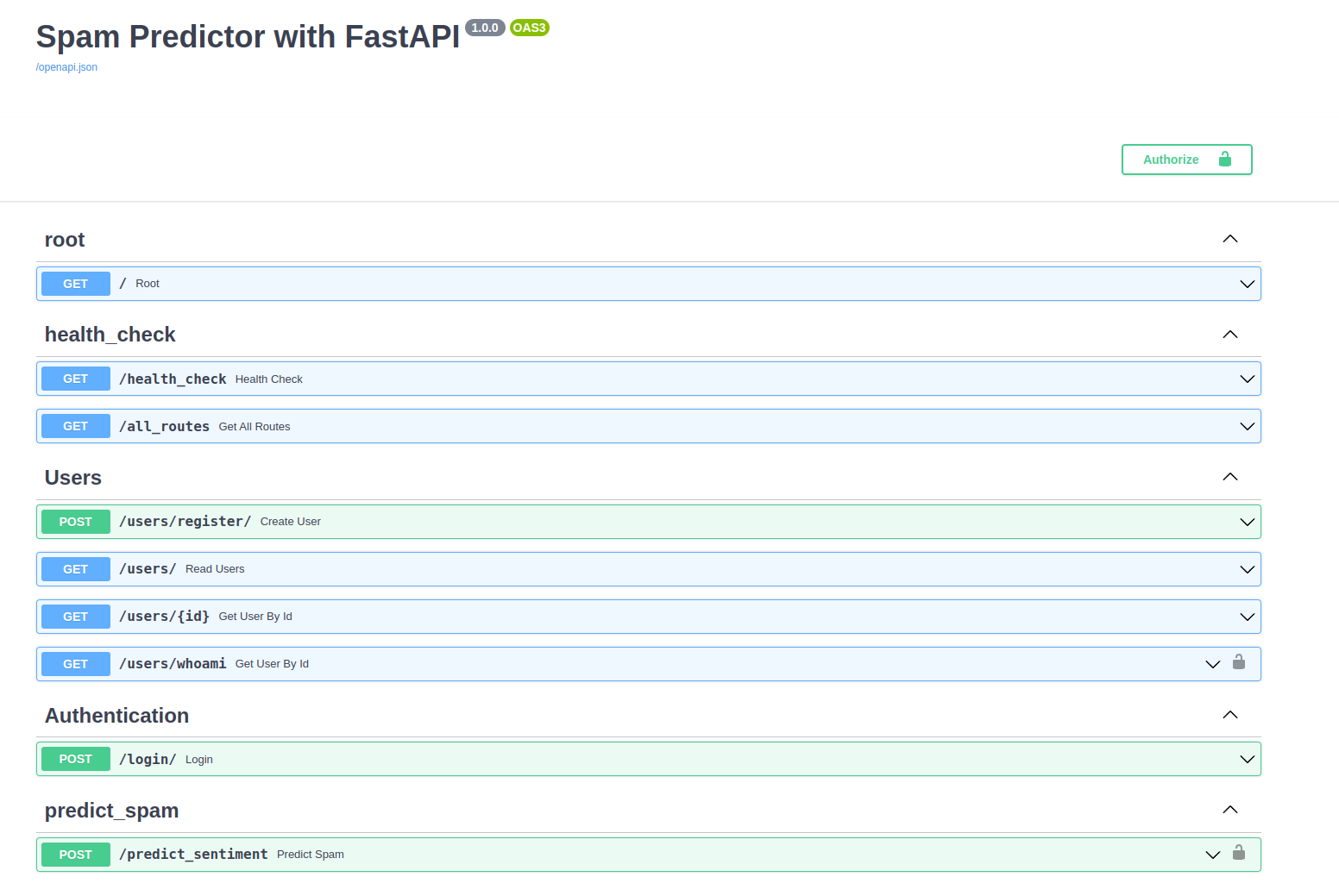
Aqui deixo registrado meus agradecimentos Pydantic!
Repare que os endpoints e os métodos possíveis de utilizam já foram carregados, caos abra cada um deles, a forma de utilizá-los estará preenchida. Note também que os endpoints /users/whoami e /predict_sentiment possuem um cadeado do lado direto, indicando que é necessária a autenticação. A autenticação deve ser feita no endpoint /login
Já parou para pensar como a documentação de uma API é importante? Podemos imaginar uma API como uma tomada. Não precisamos nos preocupar como a energia elétrica foi gerada ou como ele chegou até a tomada, mas temos certeza que ao ligar um dispositivo na tomada ele irá funcionar. Por isso é importante termos muito bem registrado como utilizar cada endpoint.
Alembic - Uma ferramenta extremamente versátil para migração do banco de dados.
Como já falamos sobre o endereço de conexão com o banco dados obtido do arquivo settings, já falamos sobre a sessão assíncrona com o banco e comentamos sobre o modelos, estamos aptos a ver um pouco sobre o Alembic.
execute na linha de comando:
alembic init -t async app/database/migrationsEsse comando é responsável por gerar os scripts assíncronos do alembic. Será criado um arquivo na raiz do projeto alembic.ini e um pasta migrations dentro do caminho informado app/database/migrations
Dentro dessa pasta será necessário editar o arquivo env.py para:
# this is the Alembic Config object, which provides
# access to the values within the .ini file in use.
from app.database.base_class import Base
from app.database.session import SQLALCHEMY_DATABASE_URI
config = context.config
config.set_main_option("sqlalchemy.url", SQLALCHEMY_DATABASE_URI)
# Interpret the config file for Python logging.
# This line sets up loggers basically.
if config.config_file_name is not None:
fileConfig(config.config_file_name)
# add your model's MetaData object here
# for 'autogenerate' support
# from myapp import mymodel
# target_metadata = mymodel.Base.metadata
# target_metadata = mymodel.Base.metadata
from app.models.usermodel import UserModel # noqa
from app.models.predictions import PredictionModel # noqa
target_metadata = [Base.metadata]Feitas as alterações necessárias para que o Alembic consiga identificar como ele fará a conexão com o banco de dados e quais são os modelos que ele deverá criar deve-se executar o comando novamente na linha do terminal:
alembic revision --autogenerate -m "create first migrations"e
alembic upgrade headAssim automaticamente as tabelas serão criadas no banco dados. Com os tabelas criadas agora podemos executar pela primeira vez nossa API.
Executando a API
Ao executarmos na linha de comando:
uvicorn --host 127.0.0.1 --port 3333 app.app:app --reload
Com a API funcionando, podemos acessar o endereço no nosso navegador e utilizar a documentação iterativa:
para a acessar a API insira no navegador ou mesmo no terminal:
curl -X 'GET' \
'http://127.0.0.1:3333/'observe o número logo após o símbolo de : 3333 deve ser o mesmo inserido no comando acima logo após o --port, pois a API estará servindo nessa porta, caso altere o valor do comando será necessário alterar também a porta no navegador.
a resposta será:

Caso aponte o navegador para http://127.0.0.1:3333/docs para ter acesso a documentação dos endpoints.
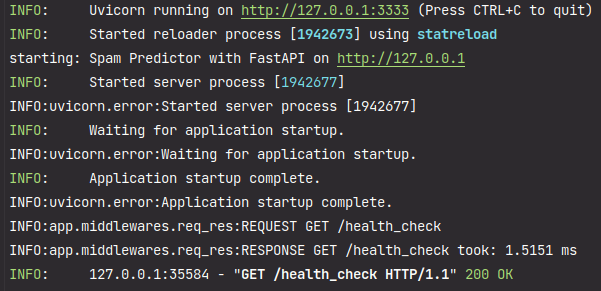
clicando no endpoint /health_check é possível utilizar o método GET e realizar uma chamada contra API.
spam_health_check.png
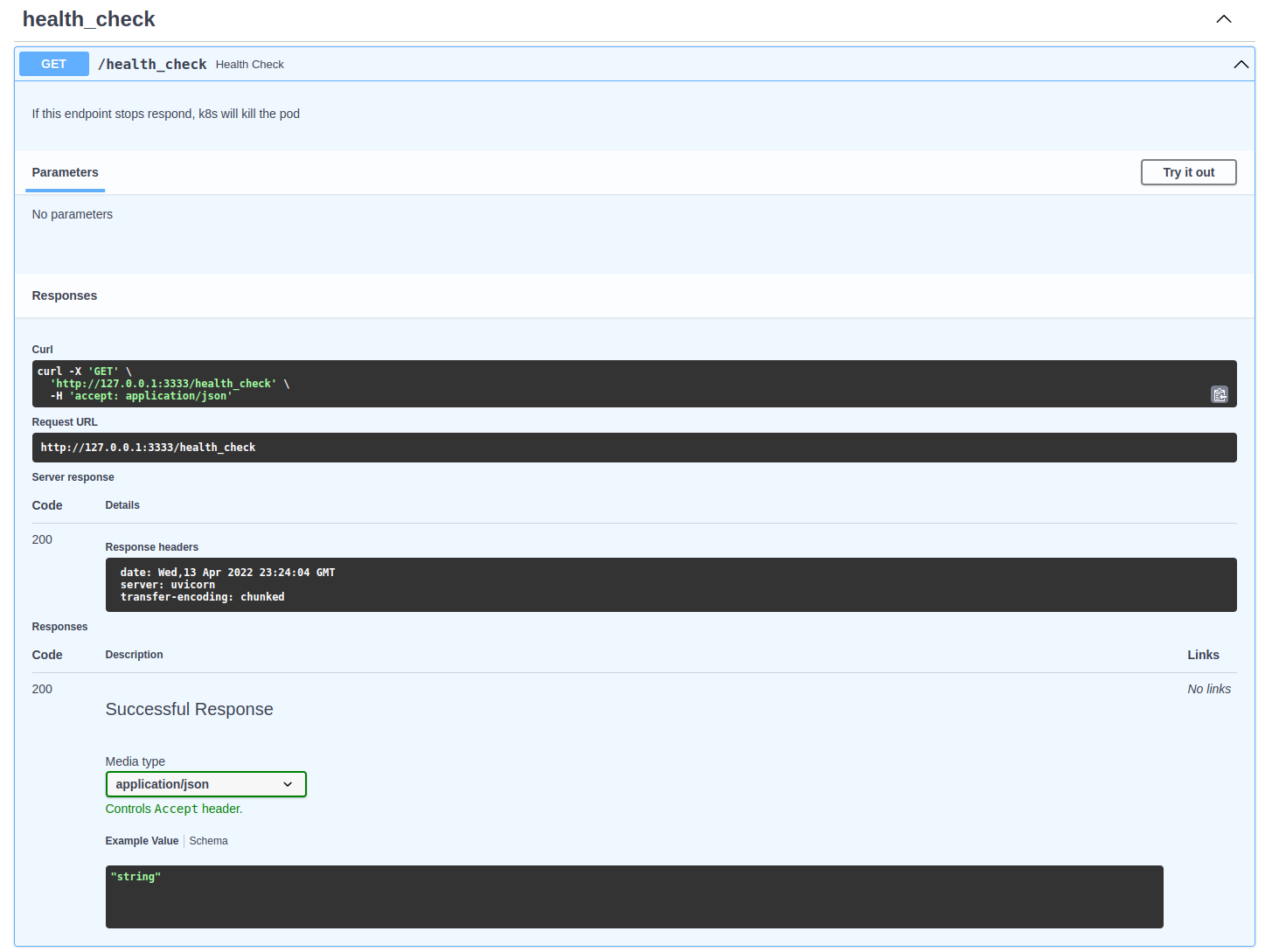
Ao clicar no botão Try it out, outro campo irá se abrir, usando o botão execute irá realizar a solicitação.
No terminal onde a API está sendo executada é possível observar os logs.
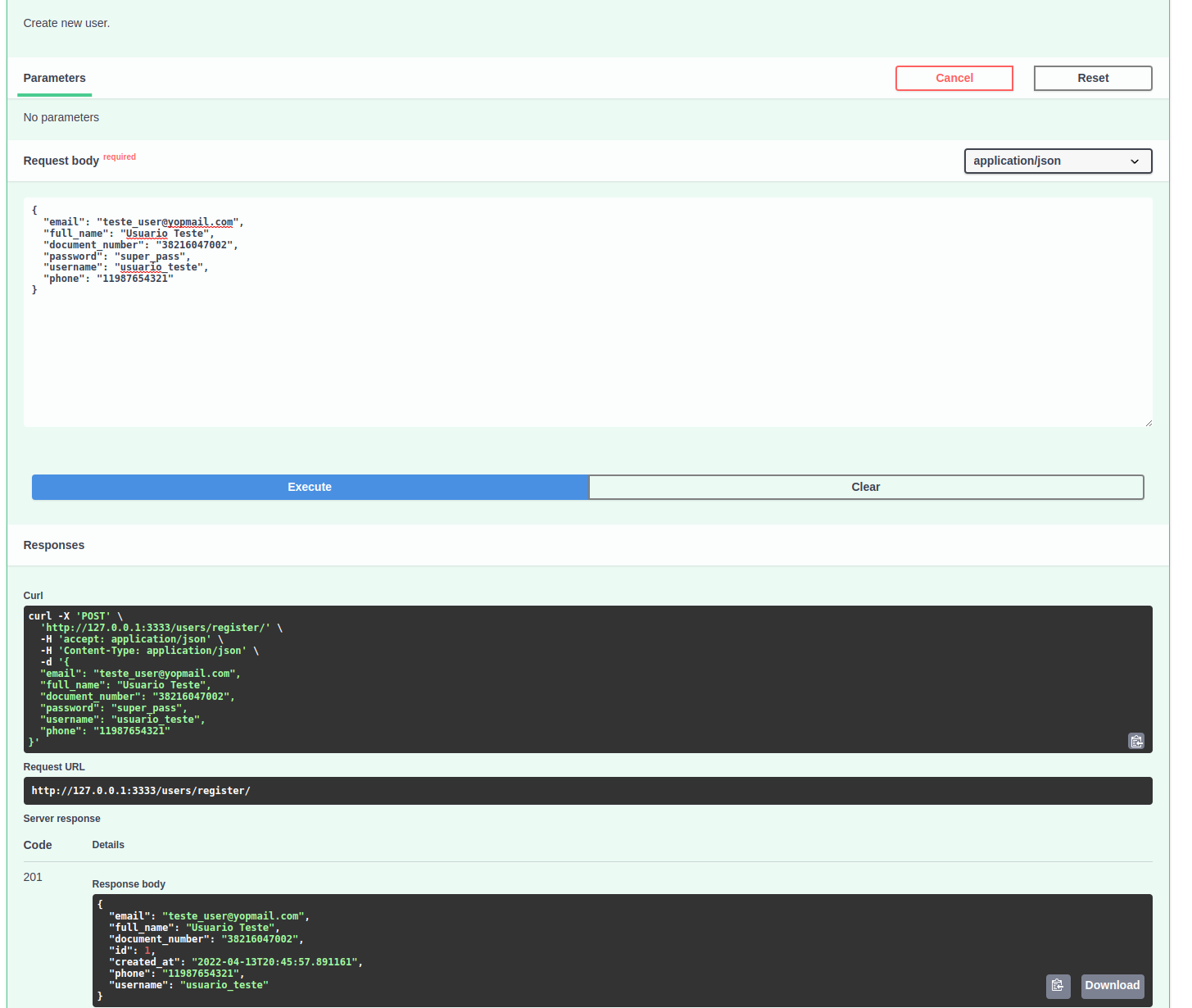
Registrando um novo usuário e autenticando
Para registrar um novo usuário utilize o endpoint /users/register/ e preencha com as informações que desejar. Lembre-se dos campos de validação que comentei anteriormente.
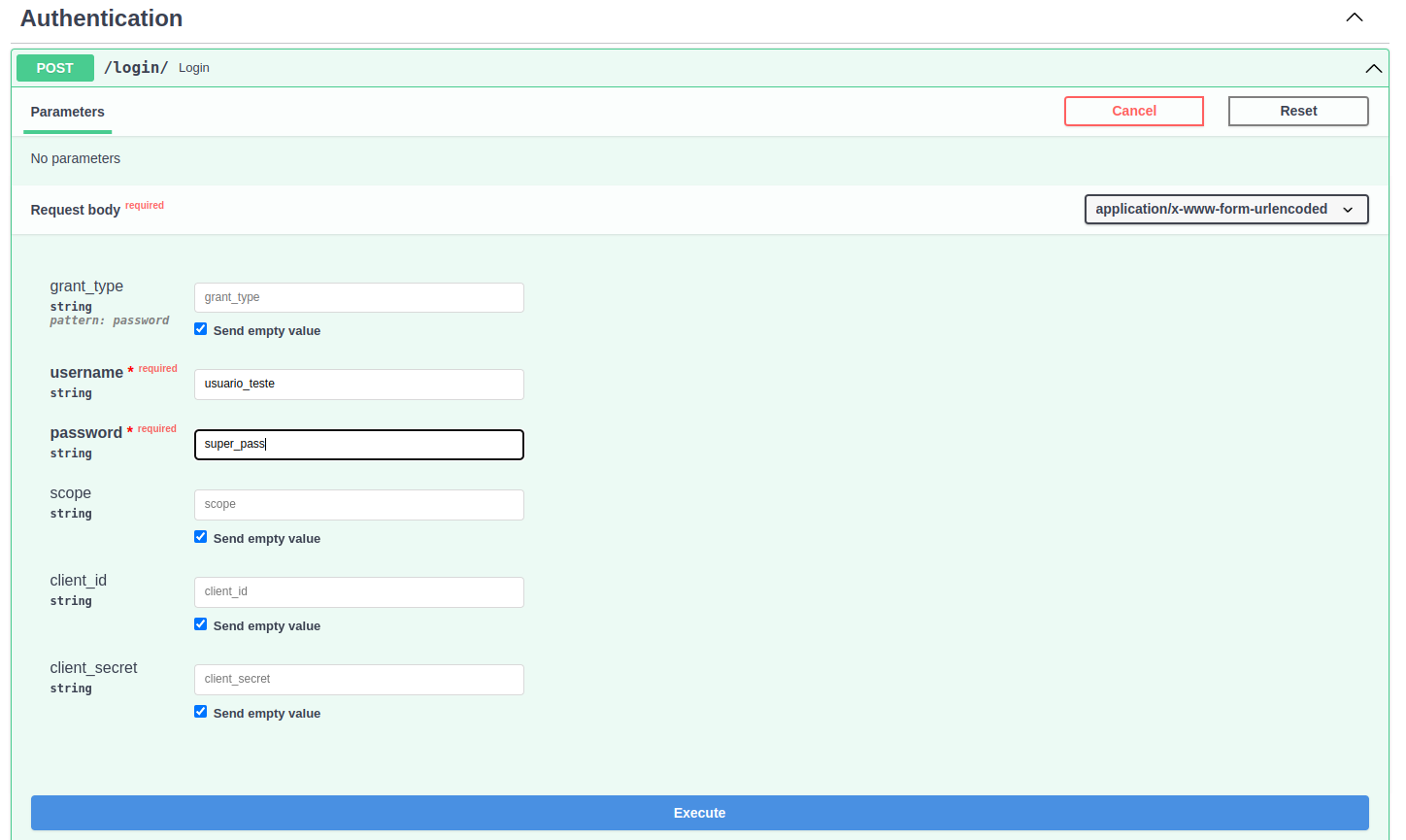
Agora para autenticar o usuário é necessário utilizar o endpoint /login/. Insira os dados utilizados no passo anterior: username e password
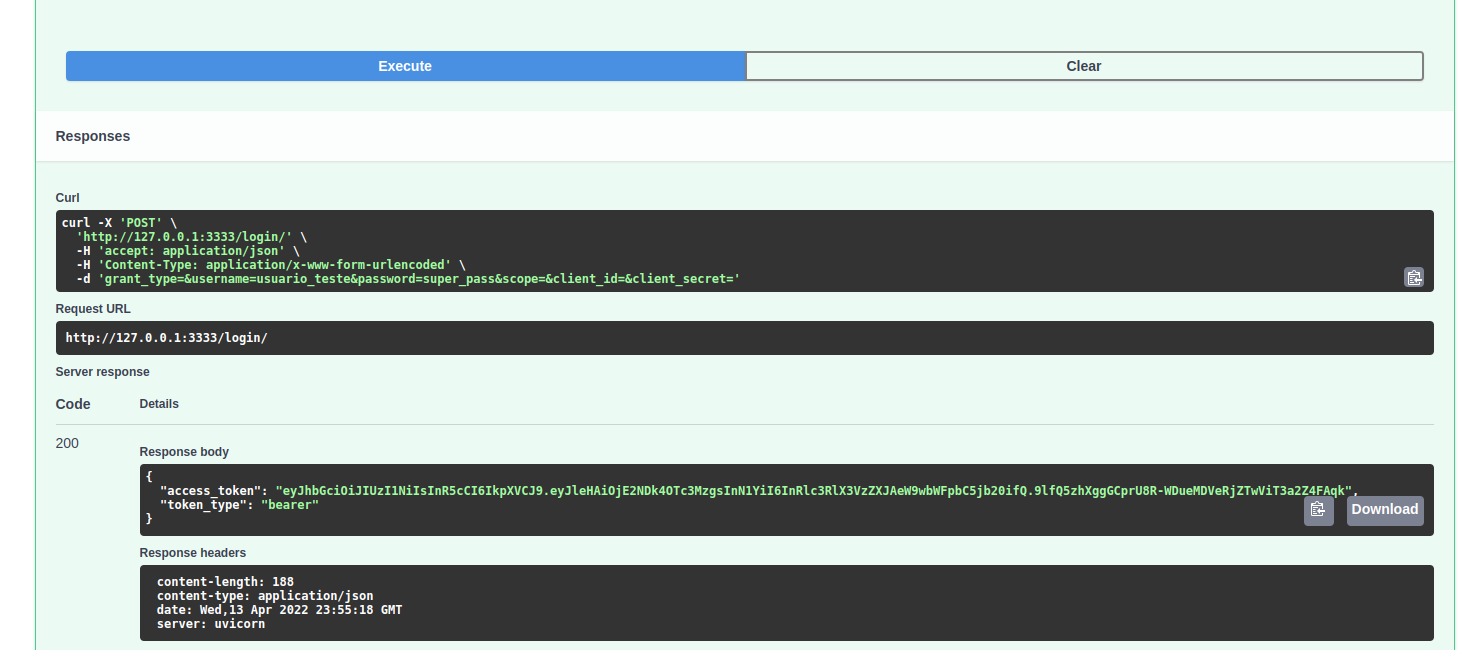
Se os dados estiverem corretos o retorno será algo como:
O modelo de Machine Learning
Como o foco desse projeto não é o modelo de machine learning em si, mas como disponibilizá-lo para utilização e produção. Eu tomei a liberdade para reaproveitar a ideia desse post e recriar o modelo.
Como já comentando em um post anterior sobre o assunto praticamente 90% dos modelos de machine learning não são disponibilizados.
O modelo foi treinando utilizando os recursos da biblioteca Scikit Learn, pois o modelo classificador multinomial Naive Bayes é adequado para classificação com características discretas (por exemplo, contagem de palavras para classificação de texto). A distribuição multinomial normalmente requer contagens de recursos inteiros. No entanto, na prática, contagens fracionárias como tf-idf também podem funcionar.
def run_model_training(X_train, X_test, y_train, y_test):
clf = MultinomialNB()
clf.fit(X_train,y_train)
clf.score(X_test,y_test)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
return clfMais detalhes sobre a implementação do modelo pode ser vista diretamente no repositório do projeto, no diretório app -> ml_models.
Após a etapa de treino o modelo é disponibilizado para uso utilizando-se a biblioteca do Python joblib, que disponibiliza um pipeline rápido, com a possibilidade de utilização de cache e computação paralela.
Utilizando o endpoint de classificação de Spam.
Na rota de utilização do modelo de machine learning, "/predict_sentiment" foram implementadas diversas funcionalidades. Inclusive a verificação se o modelo existe e foi treinado. Caso não seja encontrado o modelo, ao realizar o deploy da API o modelo será treinado utilizando como base o arquivo spam.csv localizado no diretório app -> data.
Após o usuário realizar o cadastro e login nos endpoints corretos o endpoint estará liberado para requisição.
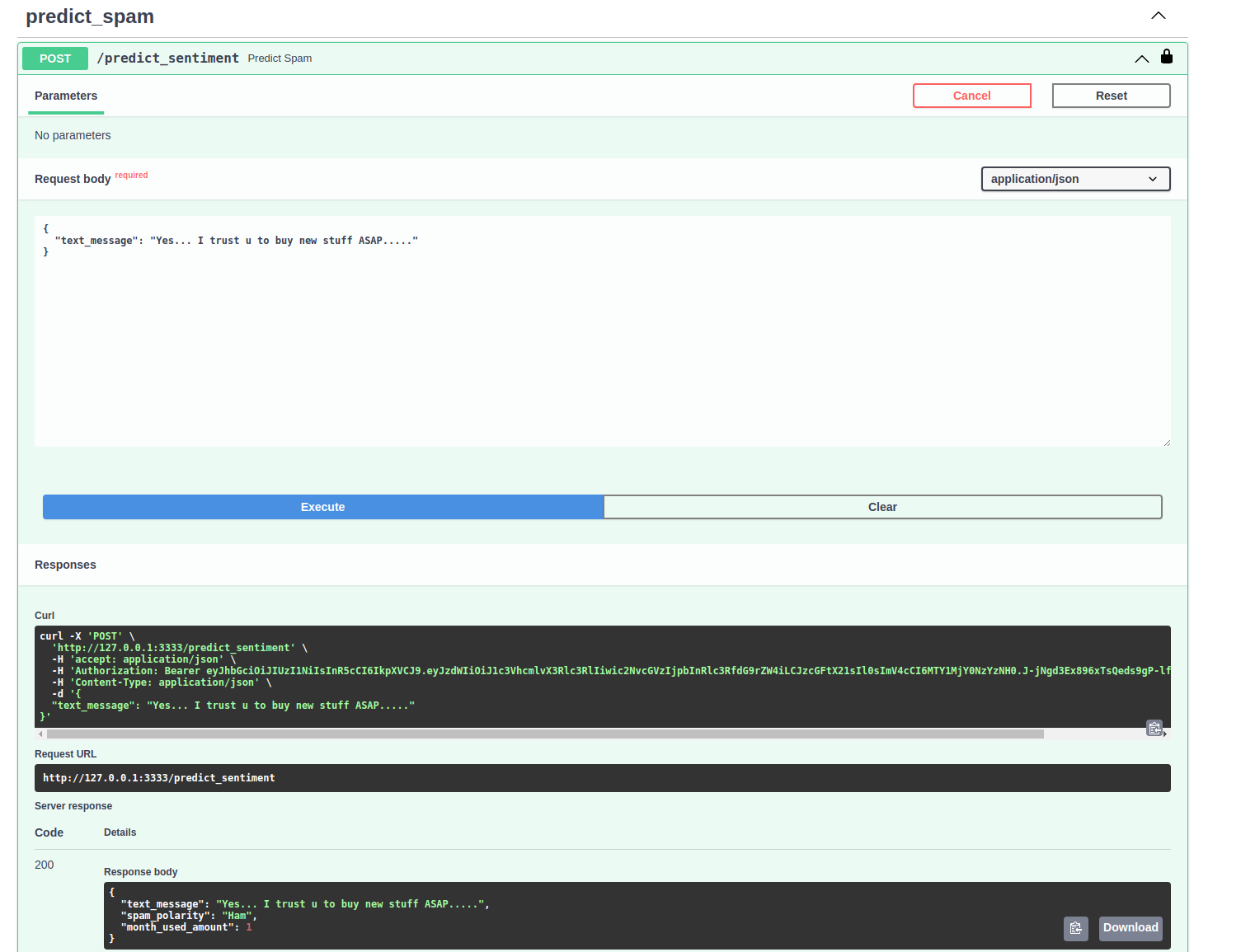
Do campo response podemos extrair a mensagem:
{
"text_message": "Yes... I trust u to buy new stuff ASAP.....",
"spam_polarity": "Ham",
"month_used_amount": 1
}No campo text_message frase que foi enviada para teste. No campo spam_polarity a saída Ham indica que o texto não foi classificado como spam e o campo month_used_amount indica quantas vezes o usuário logado utilizou o serviço.
Conclusões
Parabéns, se você leu o post até esse ponto devem ter surgido algumas dúvidas, interrogações e outros comentários. Mas ao longo desse post foi possível ver sobre a utilização de recursos modernos de python para uma solução elegante de API.
Espero que tenha atendido as expectativas em relação a proposta dos tópicos que seriam abordados e como foram discutidos aqui, caso ainda tenha dúvidas ou comentários utilize os canais de contato para discutirmos esses pontos. Questionamentos geram insights para novos posts.
Mais uma vez, esse e outros projetos podem ser acessados diretamente no meu repositório.
Recapitulando
- Utilizamos recursos do Pydantic para configurar a aplicação e gerar a documentação de cada endpoint;
- Alembic de forma assíncrona;
- Endpoint para criação e autenticação de usuários;
- Refresh tokens;
- JWT payload e JSON Web Encryption;
Próximos Post já previstos.
- Solução utilizada do docker-compose para subir a API e o banco de dados;
- Teste automatizados;
- middleware que computa o tempo entre a entrada da request e saída da response;
- logs configurados para facilitar o debug da API mesmo em ambiente de produção