Web Crawler
Aquisição de Dados
A proposta deste post é demonstrar os passos necessários criação de um web crawler para registrar o status de serviço do Metrô São Paulo e salvá-los em uma planilha de dados no Google Drive.

Para atingir o objetivo iremos escrever um web scraper capaz de receber as atualizações diretamente do site do Metro Linha 4 e extrair o status de operação.
A ideia desse post surgiu após a leitura do tópico neste link.
Esse é apenas um exemplo de aplicação de um Crawler, que pode ser utilizado para registrar preços de um produto, oportunidades de imóveis para venda ou locação, disponibilidade de servidores e assim por diante.
1. Sobre o Metrô de São Paulo
Diretamente do site oficial conseguimos entender um pouco mais sobre a história dessa importante companhia de transportes urbanos.
A Companhia do Metropolitano de São Paulo – Metrô foi constituída no dia 24 de abril de 1968. É controlada pelo Governo do Estado de São Paulo sob gestão da Secretaria de Estado dos Transportes Metropolitanos (STM). É responsável pela operação e expansão de rede metroviária e pelo planejamento de transporte metropolitano de passageiros da Região Metropolitana de São Paulo.
A rede metroviária da cidade de São Paulo é composta por 6 linhas, totalizando 101, 1 km de extensão e 89 estações, por onde passam mais de 5 milhões de passageiros diariamente. Está integrada à CPTM nas estações Luz, Tamanduateí, Brás, Palmeiras-Barra Funda, Tatuapé, Corinthians-Itaquera, Pinheiros e Santo Amaro e aos outros modais de transporte na cidade de São Paulo.
O Metrô de São Paulo é responsável pela operação das Linhas 1-Azul (Jabaquara - Tucuruvi), 2-Verde (Vila Prudente – Vila Madalena), 3-Vermelha (Corinthians-Itaquera – Palmeiras-Barra Funda) e o Monotrilho da Linha 15-Prata (Vila Prudente – Jardim Planalto), somando 69, 7 km de extensão e 62 estações. Pela rede administrada pelo Metrô, passam 4 milhões de passageiros diariamente.
2. Notebook
O notebook desenvolvido pode ser acessado no link notebook
3. O Crawler
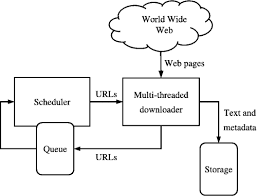
Web Crawler, bot ou web spider é um algoritmo utilizado para encontrar, ler e gravar informações de páginas da internet. É como um robô que varre o caminho indicado e captura as informações que encontra pela frente.
Um dos maiores exemplos de um web crawler é o próprio Google. Antes do site estar disponível para pesquisa, um robô lê o web site e cataloga as informações de forma a serem recuperadas numa busca futura.
Uma das ferramentas mais utilizadas em Python para criação de algoritmos dessa modalidade é o BetifulSoup. Outras informações sobre os recursos podem ser consultadas diretamente na documentação original, pelo link.
ATENÇÃO
Antes de iniciar o processo consulte sobre as normas do site sobre a utilização de robôs indexadores, que devem estar configuradas em www.seusite/robot.txt
O robots.txt é um arquivo deve ser salvo na pasta raiz do seu site, e indica para os robôs de busca quais as páginas de seu site você não deseja que sejam acessadas por estes mecanismos de pesquisa.
Isso ajuda a controlar o acesso de algumas informações importantes, como infográficos e detalhes técnicos de produtos.
Entretanto no site da ViaQuatro esse arquivo não foi configurado, pode ser um indicativo que o responsável pelo site não limitou o acesso a essas ferramentas.
Passos Iniciais
# importando as bibliotecas necessárias
from bs4 import BeautifulSoup
import requests
# executando o request
home_request = requests.get('http://www.viaquatro.com.br')
# recuperando todas informações em forma de texto
home_content = home_request.text
soup = BeautifulSoup(home_content, 'html.parser')
#verificando o título da página
soup.titleNessa etapa inicial importamos as bibliotecas necessárias e fixamos a url alvo para o crawler buscar as informações.
Da biblioteca nativa do Python utilizamos o Requests que permite o envio de um pacote de requisição HTTP de forma extremamente fácil, mantendo a conexão ativa durante o tempo necessário de forma automática.
E com a biblioteca BeatifulSoup executamos o parser da página e extrairmos as informações que desejamos, nesse caso para confirmar se tudo está funcionando executamos o soup.title para extrair o título da página.
Status de Operação
O próximo passo é executar a inspeção do site e focarmos exclusivamente na informação que desejamos obter Status de Operação .
Para inspecionar o site no Chrome utilize a tecla F11 e clique no quadro que deseja, podemos ver que as informações estão dentro da classe html: class_=operacao.
Iremos direcionar nosso robô para extrair os dados dessa classe html.
operation_column = soup.find(class_= "operacao")Entretanto dentro dessa classe há uma série de informações que não necessitamos. Iremos criar um filtro de forma a alinhar numa lista que iremos criar o nome da linha e do filtro obter o status de operação.
Para facilitar o armazenamento correto, iremos criar duas listas com os nomes das linhas do Metrô e CPTM respectivamente, para receber o Status de Operação de cada linha
#criando lista das linhas do Metro
linhas_metro = ['azul', 'verde', 'vermelha', 'amarela', 'lilás', 'prata']
# criando lista das linhas CPTM
linhas_cptm = ['rubi', 'diamante', 'esmeralda', 'turquesa', 'coral', 'safira', 'jade']
# criando uma lista única
linhas = linhas_metro + linhas_cptm
#preparando a lista para obter as informações do crawler
extracted_status = {linha:'' for linha in linhas}
extracted_statusAgora que possuímos o local para armazenamento do status vamos realizar um filtro na informações obtidas no parser e arquivá-las na linha do metrô correspondente. Ao final iremos obter a data e hora da última atualização.
lines_containers = operation_column.find_all(class_ = "linhas")
for container in lines_containers:
line_info_divs = container.find_all(class_ = "info")
for div in line_info_divs:
line_title = ''
line_status = ''
spans = div.find_all("span")
line_title = spans[0].text.lower()
line_status = spans[1].text.lower()
extracted_status[line_title] = line_status
# Extraindo a data e horário da última atualização do site.
time_data = soup.find('time').text4. Salvando os resultados
Até aqui tudo fácil e rápido, mas podemos ainda utilizando uma planilha do google drive armazenar as informações coletadas para estudos futuros.
Então vamos quais seriam os próximos passos?
- Como obter as informações de acesso e autorizar o acesso a planilha?
- O notebook irá solicitar as informações de acesso do Google Drive
- Escrever as informações obtidas numa planilha que estará compartilhada publicamente.
Para a primeira etapa siga o procedimento da documentação oficial:
Acesse a Página de Desenvolvedor do Google diretamente do link: https://console.developers.google.com/e depois:
- Habilitar o acesso da API Access para o projeto caso você ainda não tenha feito.
- Navegue até “APIs & Services > Credentials” e escolha “Create credentials > Service account key”.
- Preencha o formulário
- Click “Create key”
- Selecione “JSON” e clique em “Create”
No último passo será gerado um arquivo .json para ser salvo em seu computador. Guarde esse arquivo.
Lembre-se de salvá-lo em uma pasta de fácil acesso, pois ele será utilizado para permitir o notebook acessar a planilha. Depois criei uma nova planilha diretamente no Google Drive e compartilhe com o e-mail castrado na sua API, se você não se recorda, abra o arquivo json que você acabou de salva e busque a informação no campo client_email .
Dessa forma você não expõe seus dados na internet e esses arquivos ficam salvos temporariamente na pasta de arquivos do notebook em questão, mas toda vez que você rodar o script precisará enviar novamente os arquivos.
No meu caso abri uma subpasta na minha pasta de Projetos com o nome de MetroSP-Crawler, assim fica fácil de lembrar onde o arquivo está salvo.
from google.colab import files
import json
# fazendo o upload da credencial gerada anteriormente.
uploaded = files.upload()
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(
name=fn, length=len(uploaded[fn])))
# lendo as informações do arquivo
data = next(iter(uploaded.values()))
key = json.loads(data.decode())
# para facilitar iremos renomear o arquivo json para auth.json
import glob
import os
for source_name in glob.glob("/content/*.json"):
path, fullname = os.path.split(source_name)
basename, ext = os.path.splitext(fullname)
target_name = os.path.join(path, '{}{}'.format('auth', ext))
os.rename(source_name, target_name)
import gspread
from oauth2client.service_account import ServiceAccountCredentials
scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive']
creds = ServiceAccountCredentials.from_json_keyfile_name('auth.json', scope)Depois que você rodar o script na primeira vez pode comentar esse bloco anterior, pois a autenticação já estará validada.
Agora vamos autorizar o acesso utilizando nossas credenciais e inicializar a planilha.
Nesse ponto é necessário observar o id da planilha que pode ser obtido abrindo a planilha em uma outra janela e copiando do endereço do navegador o trecho equivalente destacado em negrito: ‘docs.google.com/spreadsheets/d/10MQxF_-WHXFpYaM_FJWwtPGtF3zjp2_WVnQ_OtC3pdA/edit#gid=0
#autorizando o acesso
client = gspread.authorize(creds)
# identificando a planilha
SPREADSHEET_ID = "10MQxF_-WHXFpYaM_FJWwtPGtF3zjp2_WVnQ_OtC3pdA"
# abrindo a planilha - atenção ao nome da aba que você vai usar
data_sheet = client.open_by_key(SPREADSHEET_ID).worksheet("data")
# para registrar o status obtido em diferentes linhas
for linha in linhas:
data_sheet.append_row([time_data, linha, extracted_status[linha]])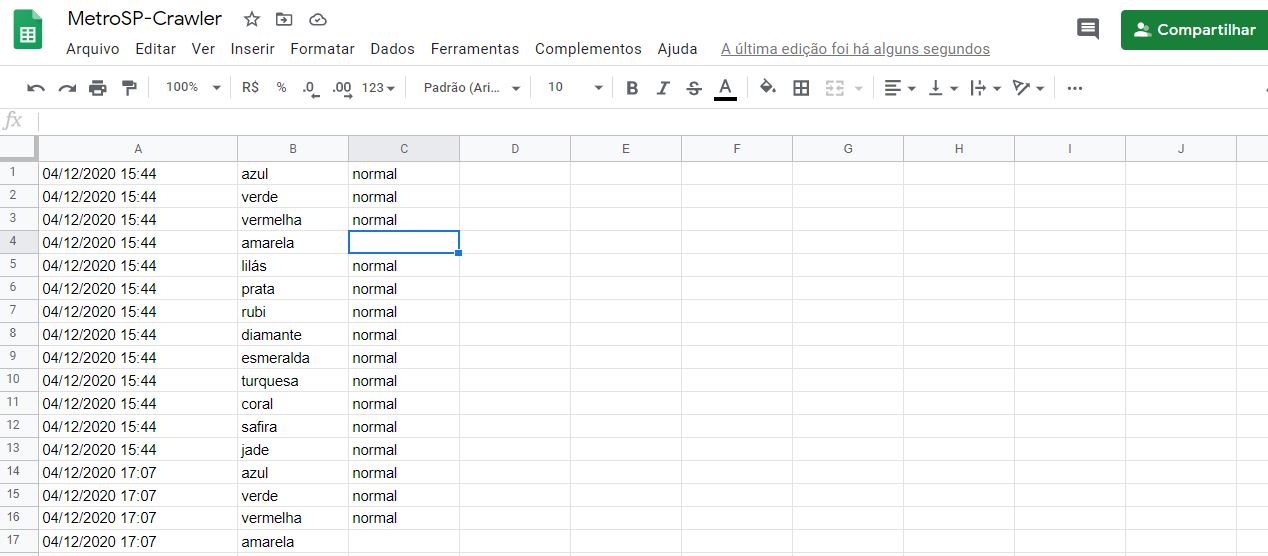
Conclusão
Até então não havia abordado ainda questão de aquisição de dados, entretanto com poucos passos é possível criar um crawler e obter qualquer informação que esteja disponível na internet. O passo mais difícil é autorizar um arquivo no Google Drive para receber as informações desse spyder, mas muito motivado pela própria segurança do sistema.
O próximo passo é automatizar o script para que rode de tempos e tempos, isso pode ser feito utilizando um Raspberry devido ao baixo custo e consumo de forma, incluindo a rotina no CronTab do sistema.
Novamente fica o alerta para sempre consultar o arquivo robots.txt e verificar se há restrições ou não para esse tipo de ferramenta.
Você pode consultar meu portfolio de projetos no: GitHub.
Obrigado pelo seu tempo, se você gostou compartilhe também.
Na figura seguinte é possível observar de forma esquemática o funcionamento desse script